ES8.8.2北斗网格码引擎使用手册
ES8.8.2北斗网格码引擎使用手册
入门
📦 配置环境
ElasticSearch8.8.2
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-8-8-2
Java17
下载地址:https://www.oracle.com/java/technologies/javase/jdk17-archive-downloads.html
Maven3.8.2
下载地址:https://archive.apache.org/dist/maven/maven-3/3.8.2/binaries/
GDAL3.4.1
下载地址:http://download.osgeo.org/gdal/3.4.1/
📚 简介
旧版本中出现的问题
北斗网格码引擎Elasticsearch 5.3.0是一个相对较早的版本,尽管它具有一定的功能和特性,但在开发项目的实施过程中,过旧的版本暴露出了一些问题和限制。
1、在数据打码入库前需要进行大量的数据清洗工作,包括进行坐标转换、将三维数据压缩为二维数据。
2、Elasticsearch 5.3.0的geoShape空间拓扑结构不完全兼容,使得部分数据无法进行入库。
3、数据入库并没有相关的日志,使得无法验证哪一部分的数据缺漏了。
4、早期的ES引擎由于接手的开发人员过多,导致代码及其混乱,拓展功能十分困难。
新版本中将针对上述问题进行功能重构。
新版本改进的功能点
北斗网格码引擎从旧版本Elasticsearch5.3.0升级至Elasticsearch8.8.2
1、不再打码缺漏数据:旧版本中的打码缺漏数据问题得到解决。
2、减少数据清洗工作:数据入库前不必进行大量的几何修复、坐标转换等数据清洗工作。
3、继承ES8新版本特性:新版本的ELasticsearch8.8.2中,支持三维数据GeoShape格式,不必向旧版本一样需要压缩成二维后进行入库。
4、增加数据入库日志:增加了导入历史记录功能,能追踪每一份数据导入的状态,不必向往常一样需要回溯数据入库是否正常。
5、优良的代码设计:充分利用设计模式和流程引擎,即使开发新功能也能够具有良好的拓展。
6、增加自然语言支持:新增了自然语言词向量embedding检索功能。这些模糊检索可以提高用户的搜索体验,一切为了更好的搜索!
7、配备数据节点管理:新增节点注册表功能,将旧版本中的index_library_name抽象成一个逻辑集群节点,不同的index_library_name代表不同的数据存储节点。该功能底层通过连接不同的Elasticsearch (ES) 来获取客户端,然后使用此客户端代表不同的逻辑集群节点。
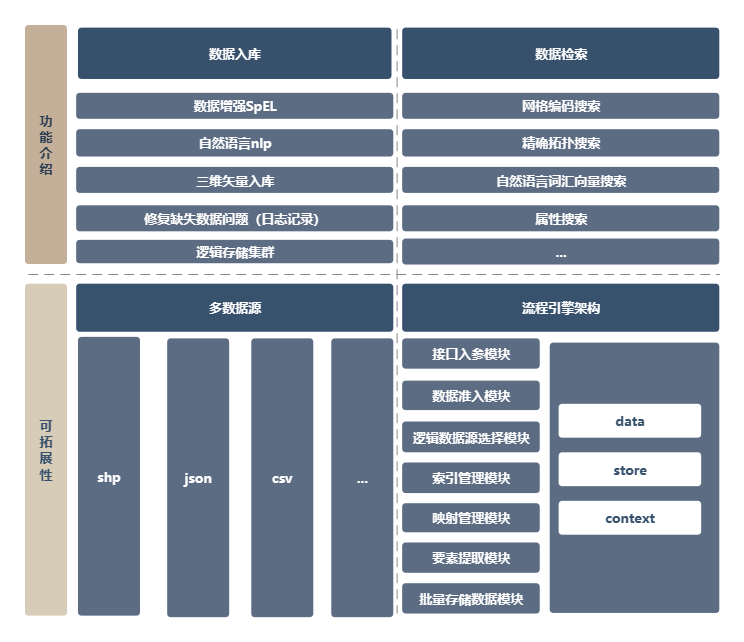
框架介绍
北斗网格码引擎是一个用于处理地理空间数据的系统。其核心是基于 Elasticsearch8.8.2 的数据存储和检索引擎,用于高效存储和查询地理位置信息。在新版网格码引擎中,我们引入了DDD领域驱动设计模式以及LiteFlow轻量化流程引擎,下述介绍中会给予说明。
📌 为什么使用ES8.8.2
1、强大的地理位置索引设计
通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。
- Elasticsearch 1.x版本:
- GeoShape字段在1.x版本中首次引入,用于索引和搜索任意的地理形状,如矩形、线和多边形。
- 该版本的GeoShape字段使用了字符串模拟的方式进行索引和搜索。
- Elasticsearch 2.x版本:
- 在2.x版本中,GeoShape字段的实现方式发生了重大改变。
- 引入了基于KD-Tree的索引结构,用于更高效地存储和搜索地理形状数据。
- 这种改进大大提高了地理形状数据的索引和搜索性能。
- Elasticsearch 5.x版本:
- 在5.x版本中,GeoShape字段的功能得到了进一步的增强。
- 引入了GeoJSON和WKT格式的支持,使得用户可以更方便地表示和索引地理形状数据。
- 该版本还引入了新的查询语法和聚合功能,使得地理形状数据的搜索和分析更加灵活和强大。
- Elasticsearch 6.x版本:
- 在6.x版本中,GeoShape字段的性能和稳定性得到了进一步的改进。
- 通过优化索引结构和查询算法,提高了地理形状数据的索引和搜索速度。
- 该版本还引入了新的地理形状查询类型,如地理形状相交、包含和距离查询,使得地理形状数据的搜索更加精确和准确。
- Elasticsearch 7.x版本:
- 在7.x版本中,GeoShape字段的功能和性能继续得到了改进。
- 引入了新的地理形状索引算法,提高了地理形状数据的索引速度和空间分析能力。
- 该版本还引入了新的地理形状聚合功能,使得地理形状数据的分析更加灵活和强大。
- ELasticsearch 8.x版本:
- 原生矢量搜索功能:Elasticsearch 8.0版本引入了一整套原生矢量搜索功能,使得用户可以使用自己的文字和语言进行搜索,并获得高度相关的结果。这些改进使得矢量搜索更容易实现,并且可以快速且大规模地比较基于矢量的查询与基于矢量的文档语料库[1]。
- NLP功能的原生支持:在Elasticsearch 8.0版本中,用户可以直接在Elasticsearch中执行命名实体识别、情感分析、文本分类等NLP功能,而无需使用额外的组件或进行编码。这一变化不仅在水平可扩展性方面取得了胜利,还为用户节省了时间和精力[1]。
- Mapping选项:在Elasticsearch 8.x版本中,可以使用
geo_shape映射将GeoJSON或WKT几何对象映射到geo_shape类型。通过显式地将字段映射为geo_shape类型,可以启用这些功能[2]。 - 索引方法:GeoShape类型通过将形状分解为三角网格,并将每个三角形作为7维点在BKD树中进行索引来进行索引。这种方法提供了几乎完美的空间分辨率,并且性能主要取决于定义多边形/多多边形的顶点数量[2]。
2、相对于ES5,ES8改进了哪些特性
-
性能提升:Elasticsearch 8引入了许多性能优化,包括更快的搜索速度、更高的吞吐量和更低的延迟。
-
新的矢量搜索功能:Elasticsearch 8引入了一整套原生矢量搜索功能,包括对近似最近邻(ANN)搜索的原生支持。可以快速且大规模地比较基于矢量的查询。
-
Rest API的统一标准:Elasticsearch 8去除了以前的Transport API、High-Level API和Low-Level API,统一采用标准的Rest API。这使得Elasticsearch更加易于使用,解决了以前API混乱的问题。
-
安全性增强:Elasticsearch 8默认开启了HTTPS,简化了安全配置。它还提供了单点登录SSO、加密通信、集群角色和属性的访问控制等安全功能,支持审计和集成第三方安全组件。
-
NLP和矢量搜索的原生支持:Elasticsearch 8直接支持NLP功能,如情感分析和文本分类,无需额外的外部组件。此外,它还增加了对矢量搜索的原生支持,可以快速进行基于矢量的查询。
-
更好的扩展性和高可用性:Elasticsearch 8在扩展性和高可用性方面有所改进,支持上百甚至上千的服务器节点,可以轻松进行节点扩容。数据多副本和多节点存储确保了单节点故障不会影响整个集群的使用。
-
更好的数据分析功能:Elasticsearch 8支持强大的数据聚合功能,可以通过搭配Kibana实现直方图、统计分组、范围聚合等数据分析功能。
⭐ DDD领域驱动设计
使用DDD的意义是什么
-
从DDD的角度看MVC架构的问题
- 代码角度
- 瘦实体模型:只起到数据类的作用,业务逻辑散落到service,可维护性越来越差;
- 面向数据库表编程,而非模型编程;
- 实体类之间的关系是复杂的网状结构,成为大泥球,牵一发而动全身,导致不敢轻易改代码;
- service类承接的所有的业务逻辑,越来越臃肿,很容易出现几千行的service类;
- 对外接口直接暴露实体模型,导致不必要开放,内部逻辑对外暴露,就算有DTO类一般也是实体类的直接copy;
- 外部依赖层直接从service层调用,字段转换、异常处理大量充斥在service方法中;
- 控制器冗余,控制器对于对象依赖过重,对象之间会产生耦合。由于Spring的存在,其实我们的开发是不符合面向对象的。
- 项目管理角度:
- 交付效率:越来越低;
- 稳定性差:不好测试,代码改动的影响范围不好预估;
- 理解成本高:新成员介入成本高,长期会导致模块只有一个人最熟悉,离职成本很大;
- 代码角度
-
MVC架构到DDD分层架构的映射
- DDD优点
- 业务逻辑清晰、业务人员也可以读。
- 业务稳定度,业务不动,代码不动。
- 防腐层隔离变化。
- 各领域内自治,可以自我发展。
- 用仓库来管理对象的存储,仓库中集成工厂Factoty/Builder应对复杂对象的组装。
- DDD优点
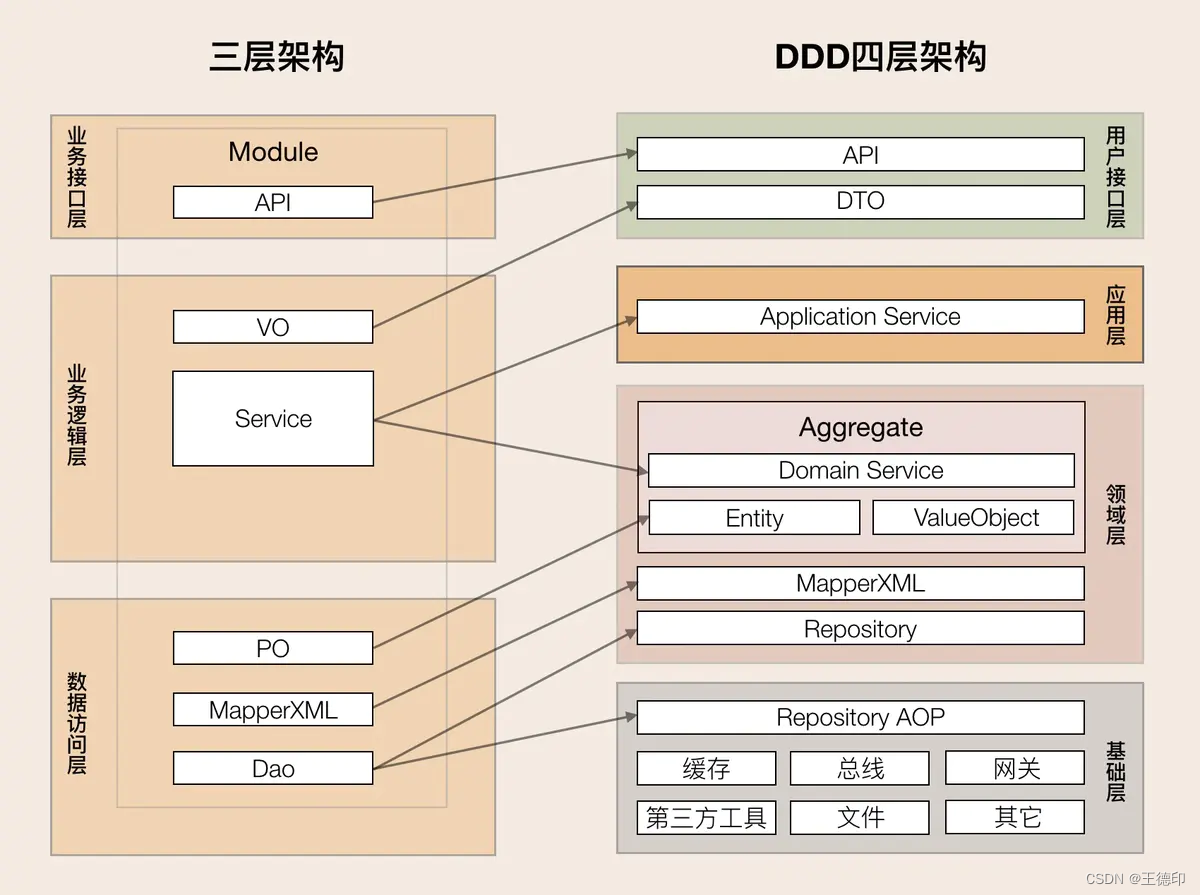
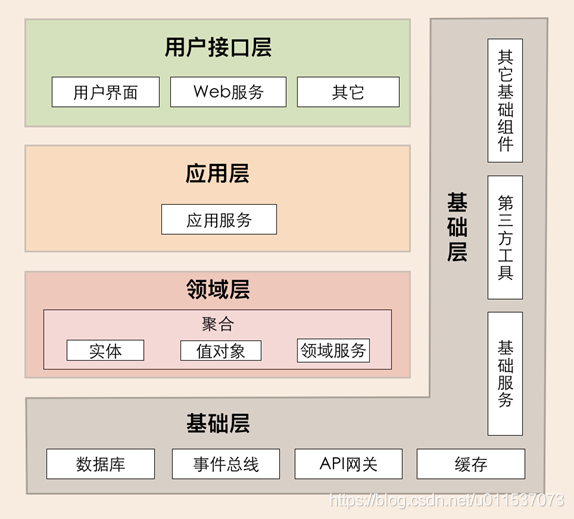
DDD四层架构的职责
它包括用户接口层、应用层、领域层和基础层,分层架构各层的职责边界非常清晰,又能有条不紊地分层协作。
重要原则:依赖倒置原则-具体依赖于抽象,而不是抽象依赖于具体。
项目示例
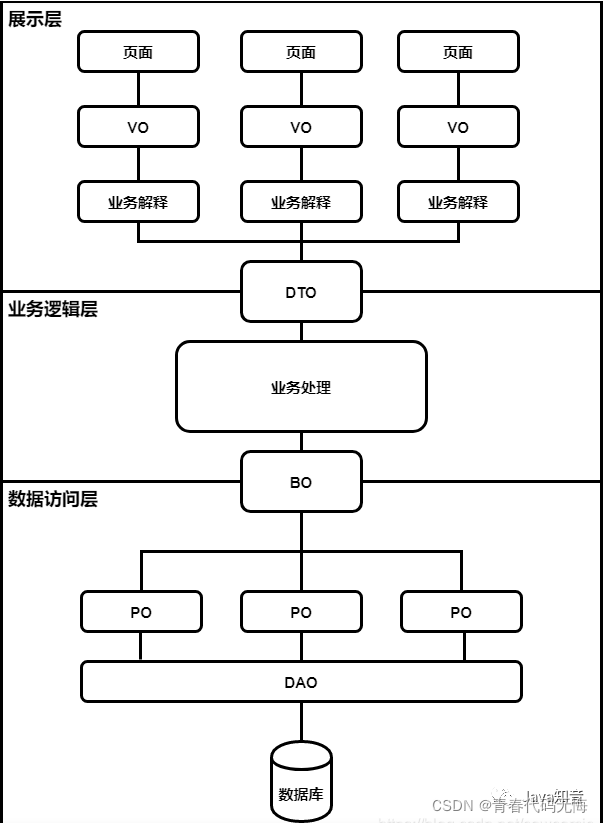
转换数据模型的目的
因为在领域驱动设计(DDD)中,转换数据模型的目的是为了在不同的领域边界之间传递和交互数据。
VO(View Object):视图对象。 DTO(Data Transfer Object):数据传输对象。 BO(Business Object):业务对象。 PO(Persistent Object):持久化对象。 DO(Domain Object):领域对象。
模型转换架构图
数据模型示例
领域模型设计是什么
简介
领域模型分为4大类:失血模型、贫血模型、充血模型、胀血模型。
注:“血”指的是Domain Object的Domain层内容
用充血模型还是贫血模型?
四种模型区别如下:
失血模型:只包含Getter/Setter的纯数据类,一般不会有这种设计。 贫血模型:包含模型属性、Getter/Setter与该模型相关的计算能力,不直接接触持久化层。 充血模型:比贫血模型多了持久化操作与绝大多数业务逻辑。 胀血模型:只有领域对象与DAO两层,在领域逻辑上封装事务
领域模型示例(IndexLibraryName)
什么是IndexLibraryName?
在我们的新版网格引擎项目中,IndexLibraryName是与Elasticsearch 节点注册表有相关联属性的一个类,在这个类中,有属性index_library_name 和 client。index_library_name是节点名,client表示与 Elasticsearch 交互的客户端。
IndexLibraryName是贫血模型还是充血模型?
贫血模型的主要特点是只包含数据和获取/设置数据的方法,而不包含任何业务逻辑。从IndexLibraryName的源代码可以看出属性index_library_name 和 client是状态(也就是数据),而 getClient 和 getIndex_library_name 是获取这些数据的方法。这个类没有包含任何业务逻辑或行为,只包含了数据和获取数据的方法。可以看出,IndexLibraryName`类是一个贫血模型的示例。
贫血模型中数据需要业务逻辑该怎么实现呢?
所有的业务逻辑(例如,如何使用 ElasticsearchClient 对象来与 Elasticsearch 交互)都需要在IndexLibraryName类之外的地方实现,例如在一个服务类 (Service) 中。
源代码
1/** 2 * 模型无状态,与spring无相关 3 * 贫血模型 : ES节点注册表 4 */ 5public class IndexLibraryName { 6 private final String index_library_name; 7 8 private ElasticsearchClient client; 9 10 public IndexLibraryName(String index_library_name,ElasticsearchClient client) { 11 this.index_library_name = index_library_name; 12 this.client = client; 13 } 14 15 public ElasticsearchClient getClient(){ 16 return client; 17 } 18 19 public String getIndex_library_name(){ 20 return index_library_name.strip(); 21 } 22}
🐾 LiteFlow工作流引擎
我们的北斗网格码引擎基于Java语言开发的轻量级工作流引擎——LiteFlow,在Spring Boot框架中集成它,从而提高我们的工作效率和开发效率
什么是LiteFlow
LiteFlow是一款轻量级的工作流引擎,它的设计思想是简单、易用、高效、可扩展。LiteFlow提供了一套非常灵活的工作流程定义方式,可以轻松地定义和管理各种类型的工作流。
LiteFlow的设计思想
LiteFlow的核心设计思想是“流程即代码”,即将业务流程和代码结构紧密耦合在一起。LiteFlow采用基于XML文件的流程定义方式,通过定义流程节点和连线来描述整个工作流程。每个流程节点都对应着Java代码中的一个方法,而连线则对应着方法之间的调用关系。这样一来,我们就可以非常直观地看到整个业务流程的处理过程,而且在修改流程时也更加方便快捷。
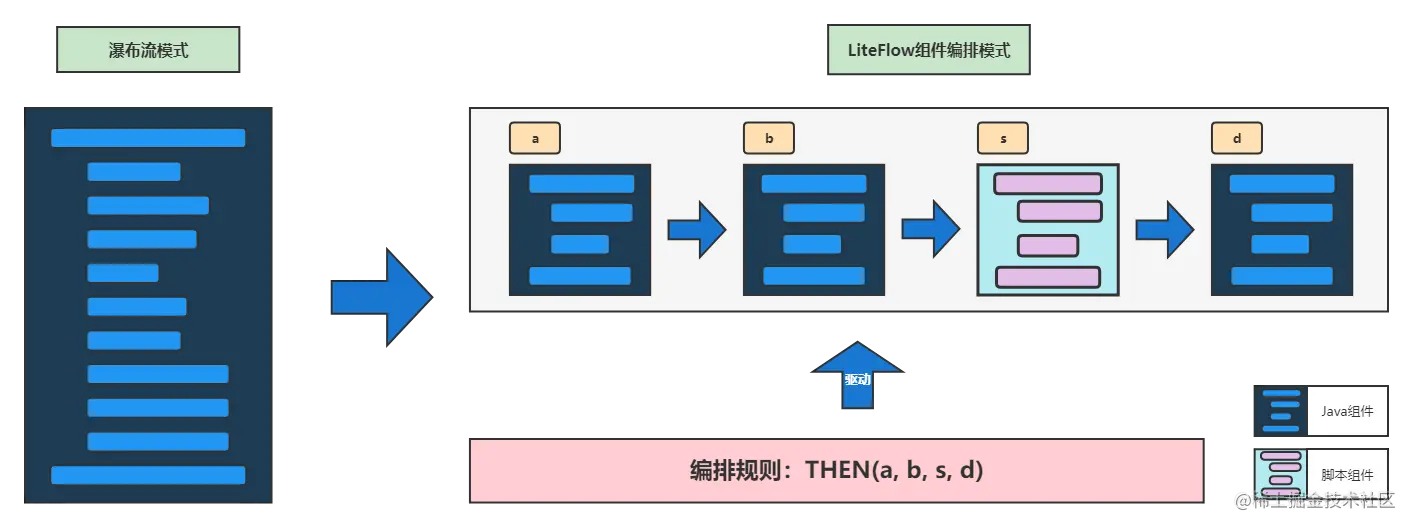
利用LiteFlow,你可以将瀑布流式的代码,转变成以组件为核心概念的代码结构,这种结构的好处是可以任意编排,组件与组件之间是解耦的,组件可以用脚本来定义,组件之间的流转全靠规则来驱动。LiteFlow拥有开源规则引擎最为简单的DSL语法。十分钟就可上手。
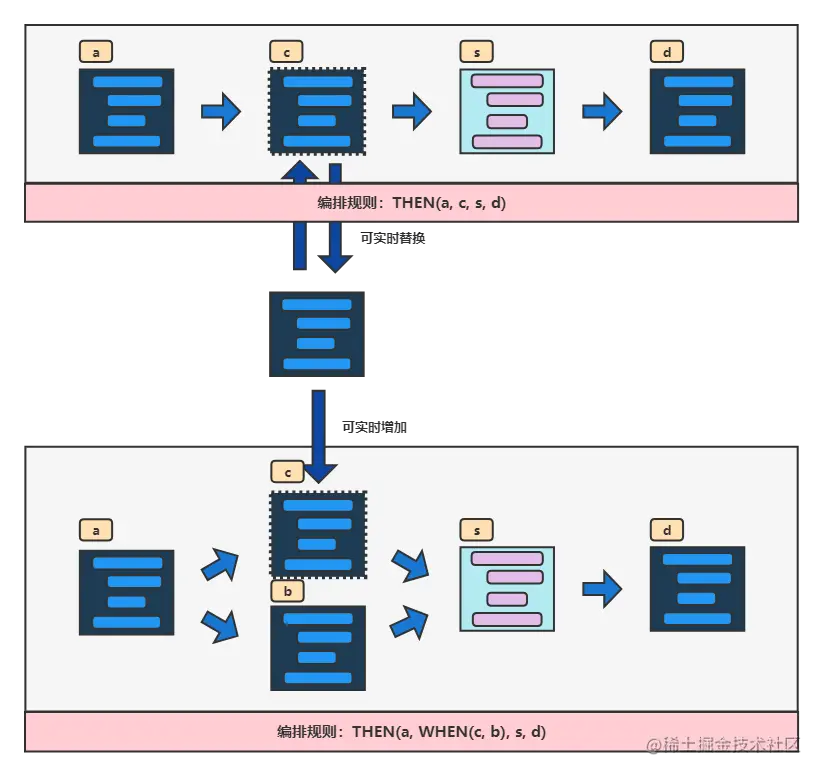
网格引擎如何使用LiteFlow
1@Service 2public class DataImportService { 3 @Resource 4 private FlowExecutor flowExecutor; 5 public LiteflowResponse start(DataImportRequest dataImportRequest){ 6 // 使用liteflow定义好的数据流程引擎,开始入库 7 LiteflowResponse response = flowExecutor.execute2Resp("dataImportChain", dataImportRequest, DataImportContext.class, FeatureIteratorContext.class, DataAccessContext.class, ImportLogContext.class); 8 return response; 9 } 10}
🚀 快速入门
注册一个ES节点
什么是IndexLibraryName?
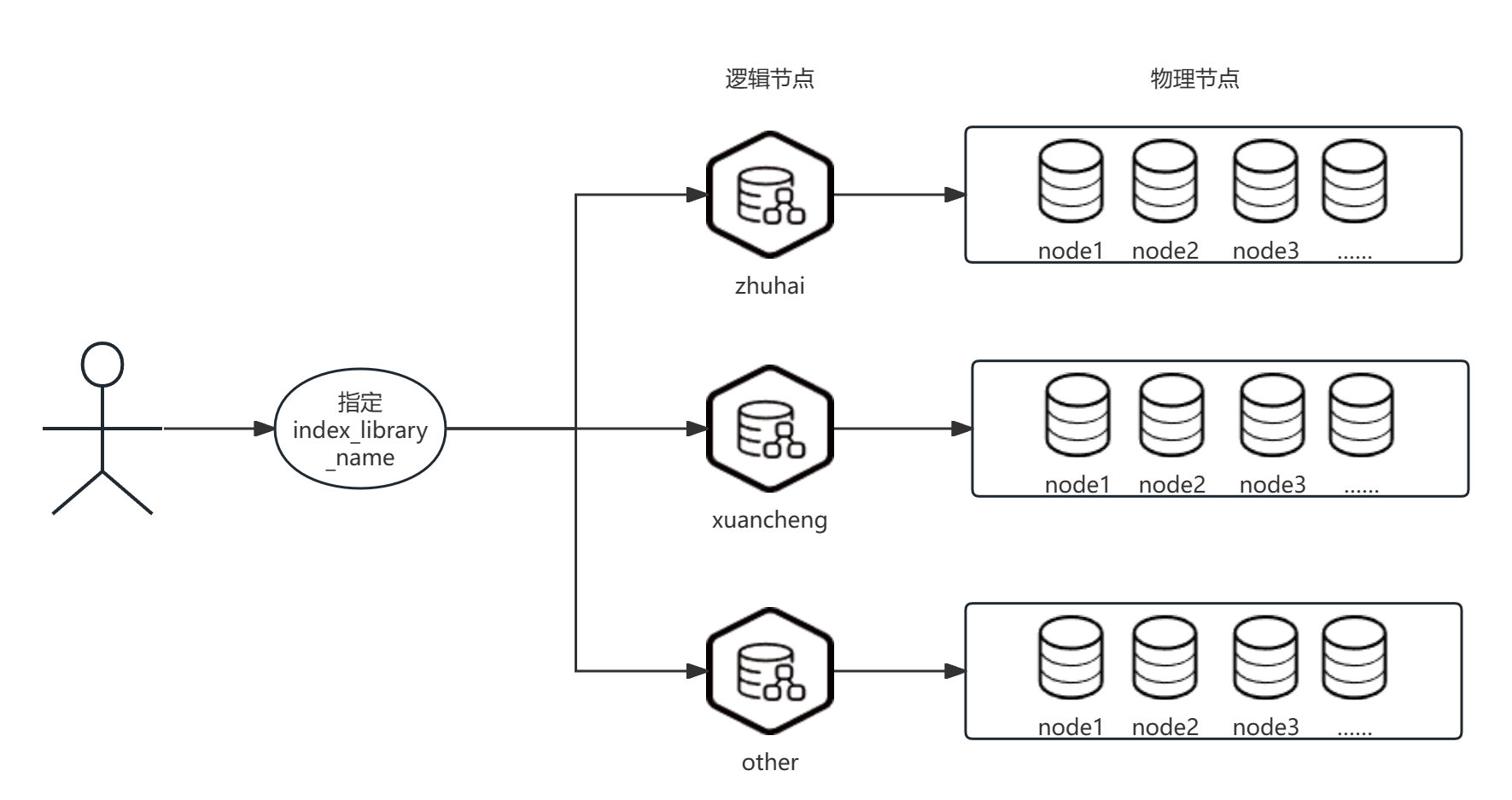
为了将一份数据存储到指定的Elasticsearch节点,我们设计了以IndexLibraryName作为数据节点的抽象概念。具体表现在一个IndexLibraryName对应于一个独立的ES集群,其设计理念是将数据源按照逻辑区域进行划分,可将数据入库到指定的ES节点中。
可以用以下的实例进行解释:假设当逻辑区域包括一个公司内部的若干个开发项目,比如"珠海项目"和"宣城项目",并且我们需要将一批空间数据存储到"珠海项目"中。在这个场景下,我们可以通过IndexLibraryName注册一个"zhuhai"的实例,并将数据存储到这个逻辑位置,从而将数据进行逻辑空间划分。
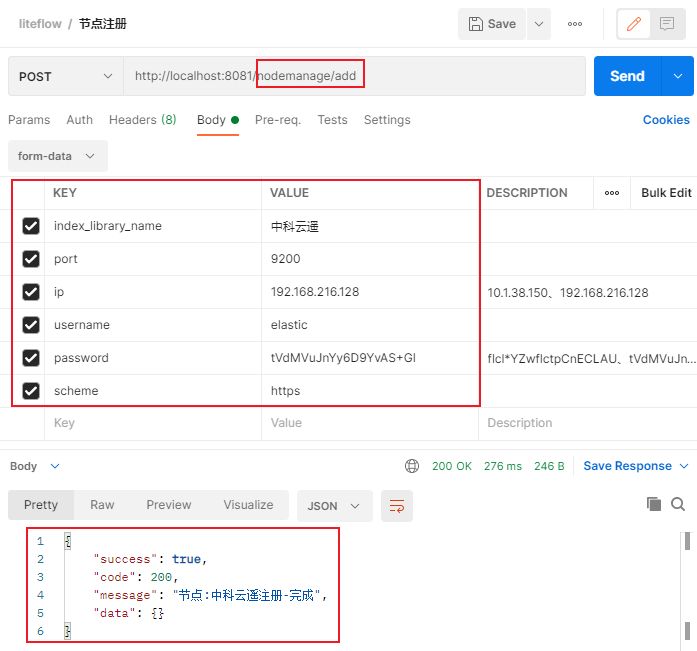
如何注册一个IndexLibraryName节点?
通过调用/nodemanage/add接口注册一个逻辑节点,传入参数含义如下:
index_library_name:逻辑节点名称。(请勿模范下图使用中文,即使可行)ip:逻辑节点所在ip地址。port:逻辑节点端口号。username:(非必填)逻辑节点账户名。password:(非必填)逻辑节点密码。scheme:http或https。
数据入库操作示例
以矢量(Shapefile)文件数据入库作为示例,调用/data/datamanage/import/vectorfile接口,每个参数具体含义如下:
index_library_name:将数据存入到哪个数据库逻辑节点。taskId:数据导入批次。数据可分批次导入,若你认为是同一批数据,他们的taskId应该相同。(请勿模范下图使用中文,即使可行)table_name:数据存放的目的索引表名。该表名即为ELasticsearch的索引名,不带前后缀(如zkyy_xxx_table)。geo_level:网格层级。big_table_name:索引大表别名,默认所有数据都属于data_big_table索引大表且不可更改,同时可自定义多个索引大表别名,以逗号分隔。cover_data:索引覆盖参数,若设定为1,则数据入库前会删除table_name对应索引,若设定为0,则会更新索引映射,在索引后追加数据。flatten_2d:数据入库时是否自动将三维的数据压缩成二维平面。1 -- 是;0 -- 否。nlp:数据入库时是否开启自然语言词向量增强功能(word embedding)。1 -- 是;0 -- 否。expression:数据增强SpEL表达式,对属性增强后入库,例如可以添加新的属性、修改属性值。file_name:存在于本地磁盘中的矢量文件。
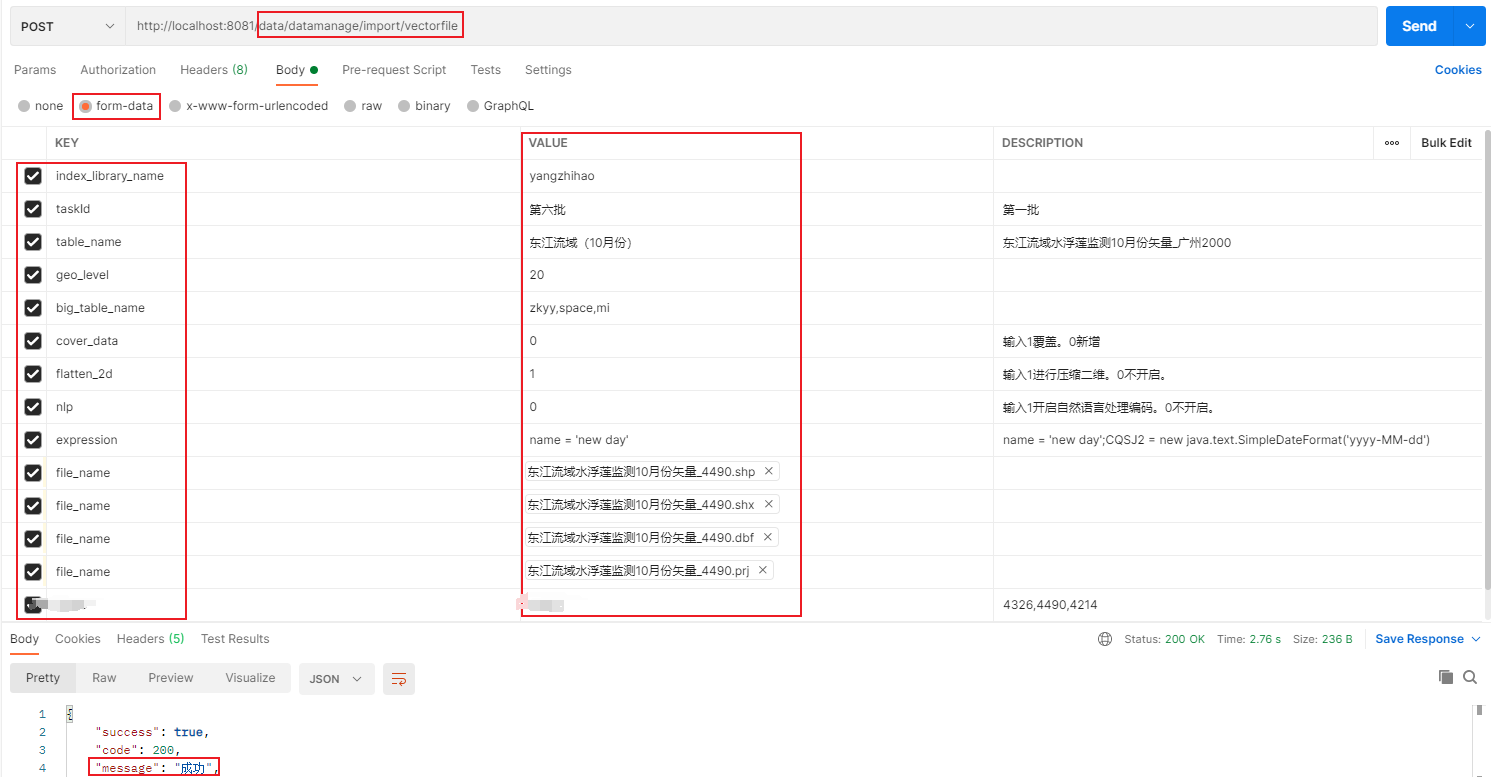
如何在代码中扩展更多数据入库格式(如csv、geojson)
com.zkyy.sandbox.facade包提供了对外的统一门户,这个包下定义了几个重要的接口:FeatureIterator(要素迭代器)、IDataAccessService(数据准入);还定义了一个实体类Features(要素)。
其中,Features类的定义如下:
1public class Features { 2 private Long fid; // 要素id 3 private Map<String,Object> fieldMap; // 属性映射 4 private Geometry geometry; // 空间信息 5}
一个完整的要素应当包括属性信息和空间信息。
- 属性信息:用Map<String,Object>代表,key为字段名,value为字段值。
- 空间信息:用org.gdal.ogr.Geometry类型代表。
FeatureIterator(要素迭代器)接口的定义如下:
1public interface FeatureIterator extends Iterator{ 2 boolean hasNext() ; // 是否存在下一个要素 3 Features next(); // 获得下一个要素 4 void init(); // 将iterator初始化,将迭代器的指针指向第一个要素 5 Features getFeature(); // 获得Features实体 6 Long size(); // 迭代器中要素的总数 7}
FeatureIterator接口继承了Java的Iterator迭代器接口,可以像个迭代器一样逐个获取矢量要素。不同的数据源有不同的实现方法,如在Shapefile文件中,可以使用gdal库逐个获取文件中的要素信息;在geojson文件中,可以使用JSONObject解析要素信息,等等……
IDataAccessService(数据准入)接口的定义如下:
1public interface IDataAccessService { 2 Boolean data_access(); // 是否准入 3}
IDataAccessService接口通过各种预校验判断此类数据源是否允许入库,如下图中的红色方框内部即为Shapefile矢量的数据准入的具体实现。若在该步骤判断为false,则直接退出数据入库流程。若接收到一个不符合入库条件的数据,该接口可提前进行中断操作,或提醒用户该数据哪些地方不符合入库条件。此接口若不实现,则默认准入。
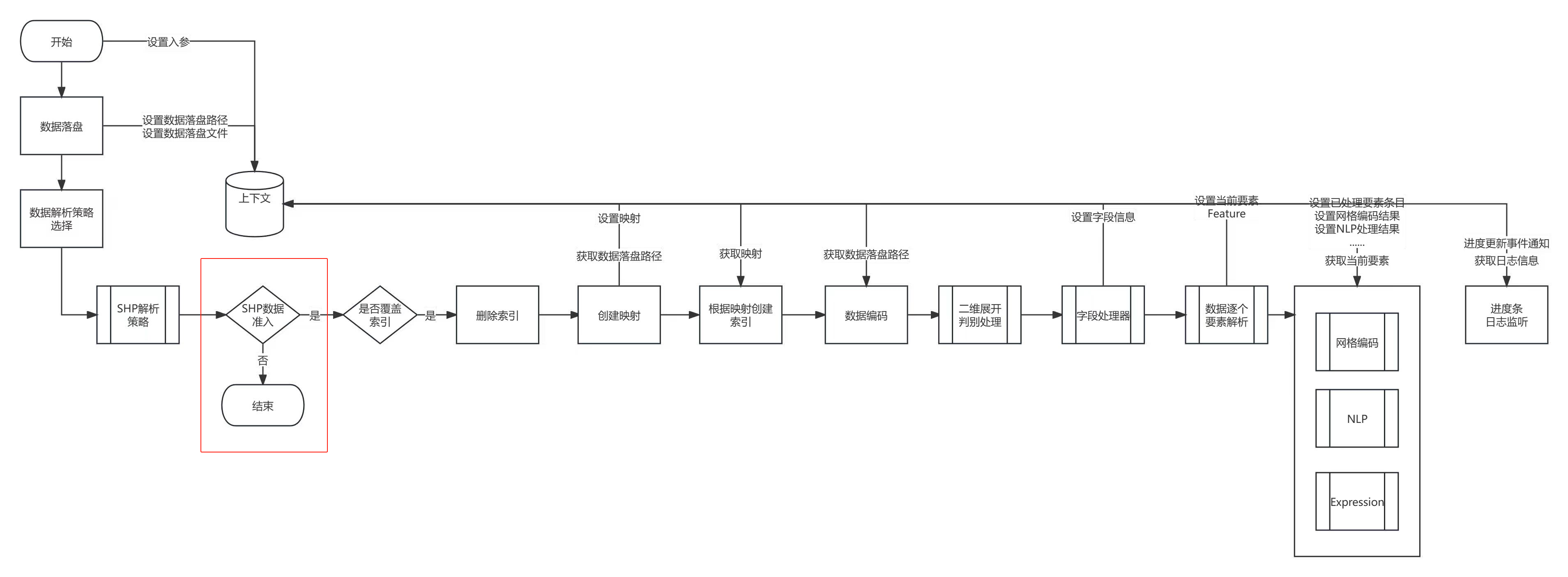
最终,在实现了上述接口后,包装成数据入库请求类DataImportRequest,调用Liteflow的流程引擎开始入库。
1// 数据入库前要包装成数据入库请求类DataImportRequest 2DataImportRequest dataImportRequest = new DataImportRequest.Builder() 3 .paramRequest(paramRequest) // 包装成paramRequest对象,这样才可以注入流程引擎打码入库。 4 .featureIterator(featureIterator) // 注入要素迭代器的具体实现 5 .dataAccessService(dataAccessService) // 注入数据准入的具体实现,可有可无,有默认策略 6 .build();
1// 开始入库 2LiteflowResponse response = dataImportService.start(dataImportRequest);
数据检索操作示例
以精确的空间查询接口为示例,调用/data/datasearch/exact/geometrysearch接口,每个参数具体含义如下:
index_library_name:指定数据库逻辑节点,将数据从此处取出。taskId:(非必填)限定仅查询该入库批次,若不填则不限定查询入库批次。big_table_names:索引大表别名,可以在多个索引大表查询数据,以逗号分隔,如:farm,ldlzzzx,bhqgdgeometry:查询给定空间范围内数据,以Geojson的形式传入,切记如果传入的是Polygon面,则最后一个点一定要和第一个点相同。query_condition:类sql的数据过滤,筛选满足条件的数据。sort_keys:返回结果以指定字段进行排序。搭配sort_orders字段使用。sort_orders:排序规则,asc升序,desc降序。搭配sort_keys字段使用。included_fields:仅返回字段。excluded_fields:仅排除字段。from,size:分页参数。from从第一页开始。
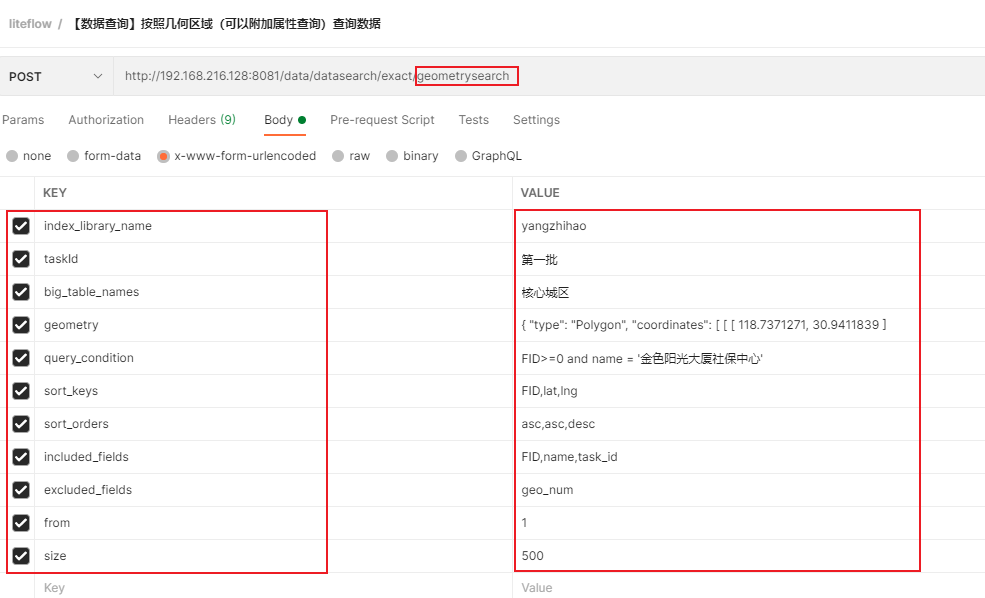
如何在代码中构建数据检索请求
(以精确拓扑检索作为示例)
1// 将vo模型转成bo模型 2GeoSpatialSearchBO geoSpatialSearchBO = DataSearchConvertor.viewObj2BussinessObj(request, indexLibraryNameFactory); 3 4// 构建空间数据查询请求 5IGeoSpatialSearchQuery dataSearchQuery = dataSearchQueryBuilder 6 .indexLibraryName(geoSpatialSearchBO.getIndex_library_name()) 7 .geometry(geoSpatialSearchBO.getGeometry()) 8 .sql(geoSpatialSearchBO.getQuery_condition()) 9 .taskId(geoSpatialSearchBO.getTaskId()) 10 .bigTableNames(geoSpatialSearchBO.getBig_table_names()) 11 .from(geoSpatialSearchBO.getFrom()) 12 .size(geoSpatialSearchBO.getSize()) 13 .includeFields(geoSpatialSearchBO.getIncluded_fields()) 14 .excludedFields(geoSpatialSearchBO.getExcluded_fields()) 15 .sortKeys(geoSpatialSearchBO.getSort_keys()) 16 .sortOrders(geoSpatialSearchBO.getSort_orders()) 17 .build(); 18 19// 发起查询请求 20DataSearchResponseVO<T> dataSearchResponseVO = dataSearchQuery.search(tClass);
功能
🍐 数据入库
简介
在我们的网格引擎项目中,数据入库功能是最核心的功能之一。
在旧版的设计中,当针对入库功能新增一个开发需求时,因为代码模块间的耦合度非常高,业务逻辑和底层实现逻辑强依赖在一起,牵一发而动全身,修改非常困难,即使花费很大心思新增开发需求完成,混乱的代码极容易出现异常,且维护难度非常高。
因此,在新版的设计中,为了使项目更注重业务逻辑,同时将底层实现逻辑耦合出来,并确保确保每个模块和类都遵循单一职责原则,我们选择使用了DDD领域驱动设计模式来设计整体架构。
如何设计数据入库的核心架构
在DDD中,领域模型的设计通常涉及到划分领域和定义聚合。我们把数据入库功能当作一个领域服务,接着对领域进行了适当的划分,将相关联的业务逻辑聚合在一起。
如图:
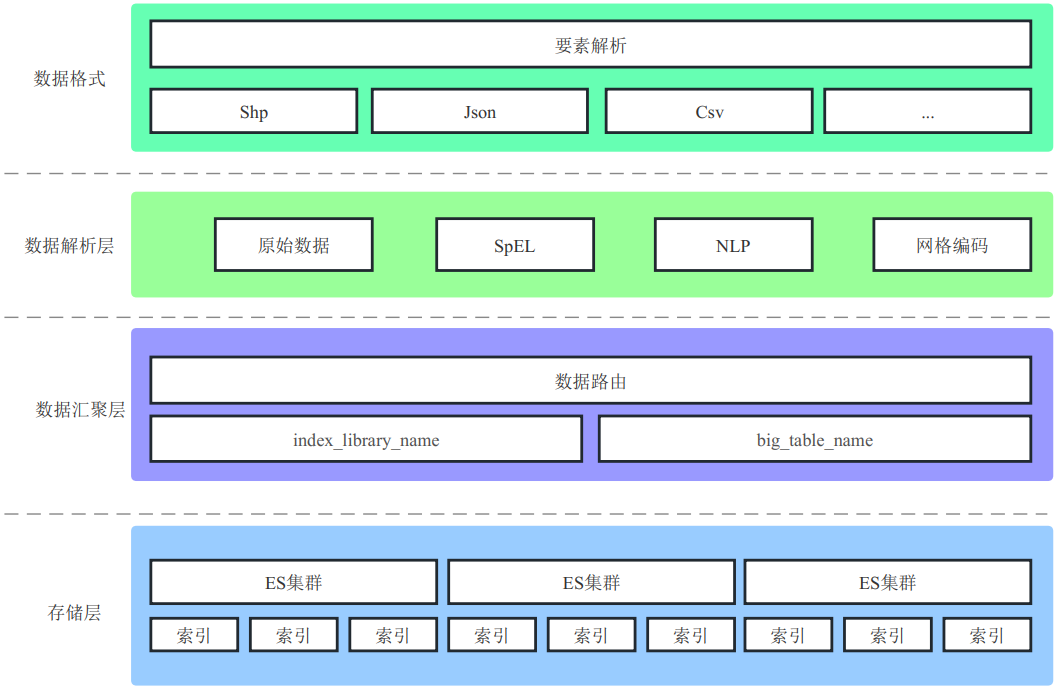
核心架构设计出来之后,为了实现架构中划分好的内容,同时将这些内容解耦,使得后续开发中新增需求、修改需求也不用花费很大力气。于是,我们决定采用工作流引擎 (LiteFlow)来管理业务流程,将要素解析、数据解析、数据批量入库、日志记录组成工作流。在LiteFlow中,组件是概念核心,它是解耦各部分底层实现逻辑的重要原因,同时,为了更加彻底的解耦组件间的关联性,我们引入了一个重要概念——上下文。
什么是上下文
在我们的网格引擎项目中,工作流引擎 (LiteFlow)来管理业务流程,使得我们只需要通过flow.el.xml的设置,即可控制组件流程,并且组件之间通过上下文(context)来进行参数和数据的传递,而不是传统的模式中的直接参数传递,这是因为每一个组件(cmp)之间都是相互独立的,不允许参数之间的直接传递。
而我们采用的 liteflow设计中,我们会在数据入库流程开始时,将入参参数包装成一个Param参数对象,并存入上下文中,上下文的使用原则是“随存随取”,也就是说,只有在需要使用某个参数时,才从上下文中取出这个参数。比如数据入库上下文,由数据入库功能业务流程所产生的所有数据都保存在这个上下文中,需要时自取。这种方式极大地简化了参数管理和数据传递的复杂性,同时也减少了资源的浪费。
如何编排组件流程
我们的网格引擎项目中,LiteFlow采用基于XML文件的流程定义方式,通过定义流程节点和连线来描述整个工作流程。于是,我们通过Liteflow框架,定义了一个名为flow.el.xml的XML流程配置,从源代码中可以知道,其描述了一个数据处理流程,包括数据入库、数据访问判断、编码流程等多个步骤。以下是对每个步骤的详细解释:
-
数据入库:通过
dataImportChain链进行数据入库操作。这个链的定义中使用了THEN关键词,表示在执行了param组件后,将执行dataAccessChain链。 -
数据访问判断:
dataAccessChain链用于判断数据是否可以访问。这个链的定义使用了IF关键词,表示如果dataAccess组件的执行结果为真,那么就执行mainChain链。 -
编码流程:
mainChain链是这个流程的主要部分,包括了数据的编码、存储和日志记录等操作。这个链的定义中使用了THEN关键词,表示首先执行coverData组件。然后,使用了WHILE和DO关键词,表示只要featureIterator组件的执行结果为真,就执行括号里的组件。在这个括号里,首先使用了WHEN关键词,表示同时执行geosot、nlp和SpelCmp三个组件,这三个组件的最大等待时间是10000秒。然后,执行dataStore和importLog两个组件。
源代码(flow.el.xml)
1<?xml version="1.0" encoding="UTF-8"?> 2<flow> 3 <!-- 数据入库 --> 4 <chain name="dataImportChain"> 5 THEN( 6 param, 7 dataAccessChain 8 ); 9 </chain> 10 <!-- 数据不准入就退出,否则进入编码流程 --> 11 <chain name="dataAccessChain"> 12 IF(dataAccess,mainChain); 13 </chain> 14 <!-- 编码流程,索引覆盖组件、网格编码组件、存储组件、日志组件 --> 15 <chain name="mainChain"> 16 THEN( 17 coverData, 18 WHILE(featureIterator).DO( 19 THEN( 20 WHEN(geosot,nlp,SpelCmp).maxWaitSeconds(10000), 21 dataStore, 22 importLog 23 ) 24 ) 25 ); 26 </chain> 27</flow>
顶层图
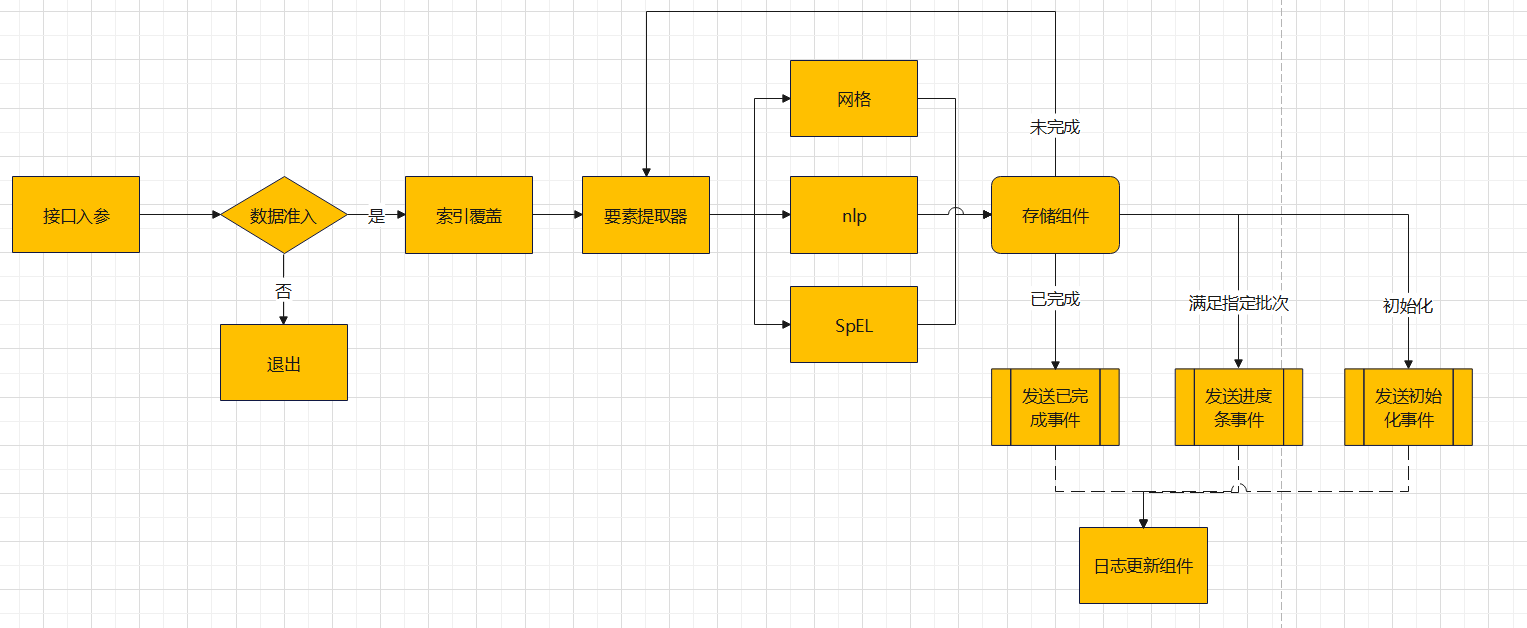
次顶层图
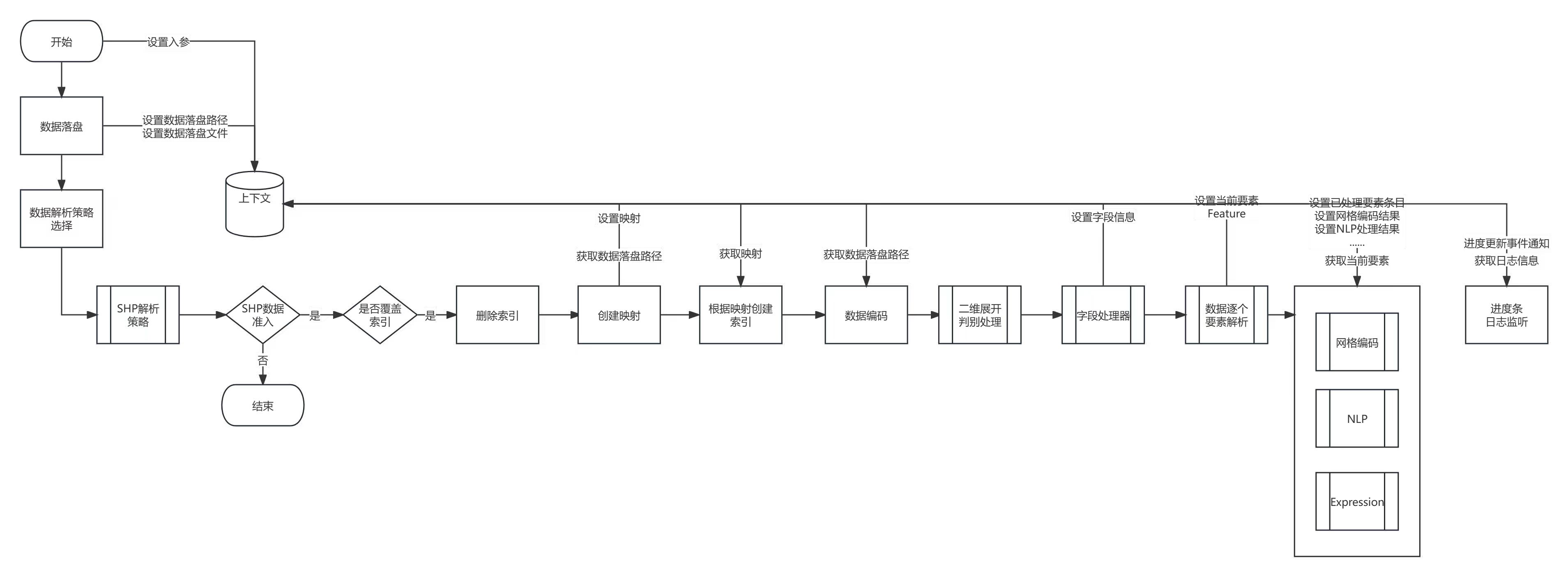
底层图
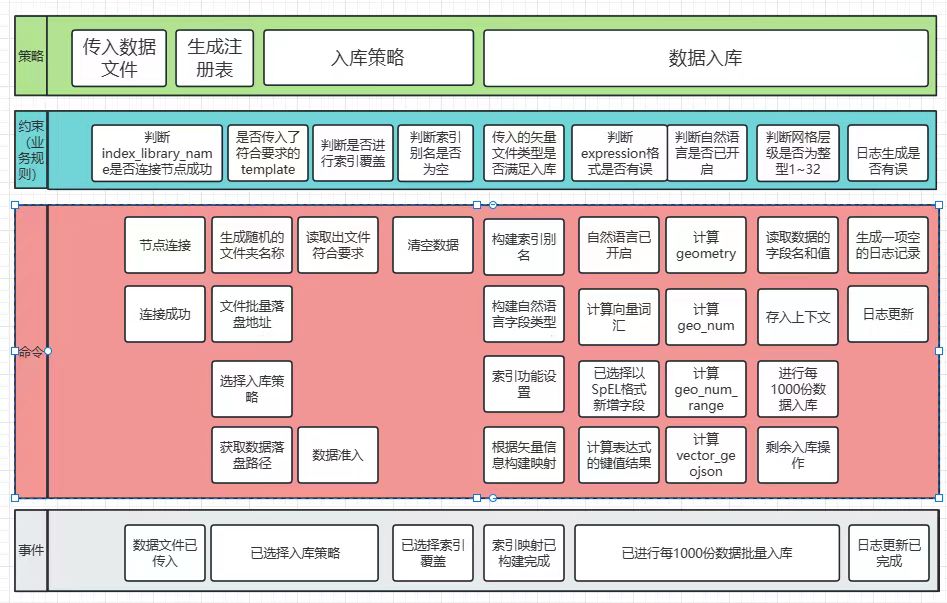
如何实现数据入库功能
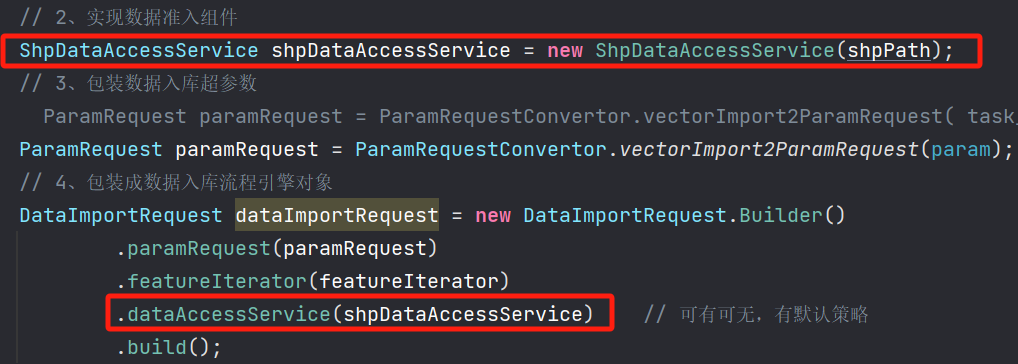
以shp格式的文件为例,param 是一个封装好的入参参数对象
1 //1、实现要素迭代器 2 ShpFeatureIterator featureIterator = new ShpFeatureIterator(shpPath); 3 // 2、实现数据准入组件 4ShpDataAccessService shpDataAccessService = new ShpDataAccessService(); 5 // 3、包装数据入库超参数 6ParamRequest paramRequest = ParamRequestConvertor.vectorImport2ParamRequest(param); 7 // 4、包装成数据入库流程引擎对象 8DataImportRequest dataImportRequest = new DataImportRequest.Builder() 9 .paramRequest(paramRequest) 10 .featureIterator(featureIterator) 11 .dataAccessService(shpDataAccessService) // 可有可无,有默认策略 12 .build(); 13 // 5、开始入库 14LiteflowResponse response = dataImportService.start(dataImportRequest);
数据入库功能是如何解耦成一个服务的
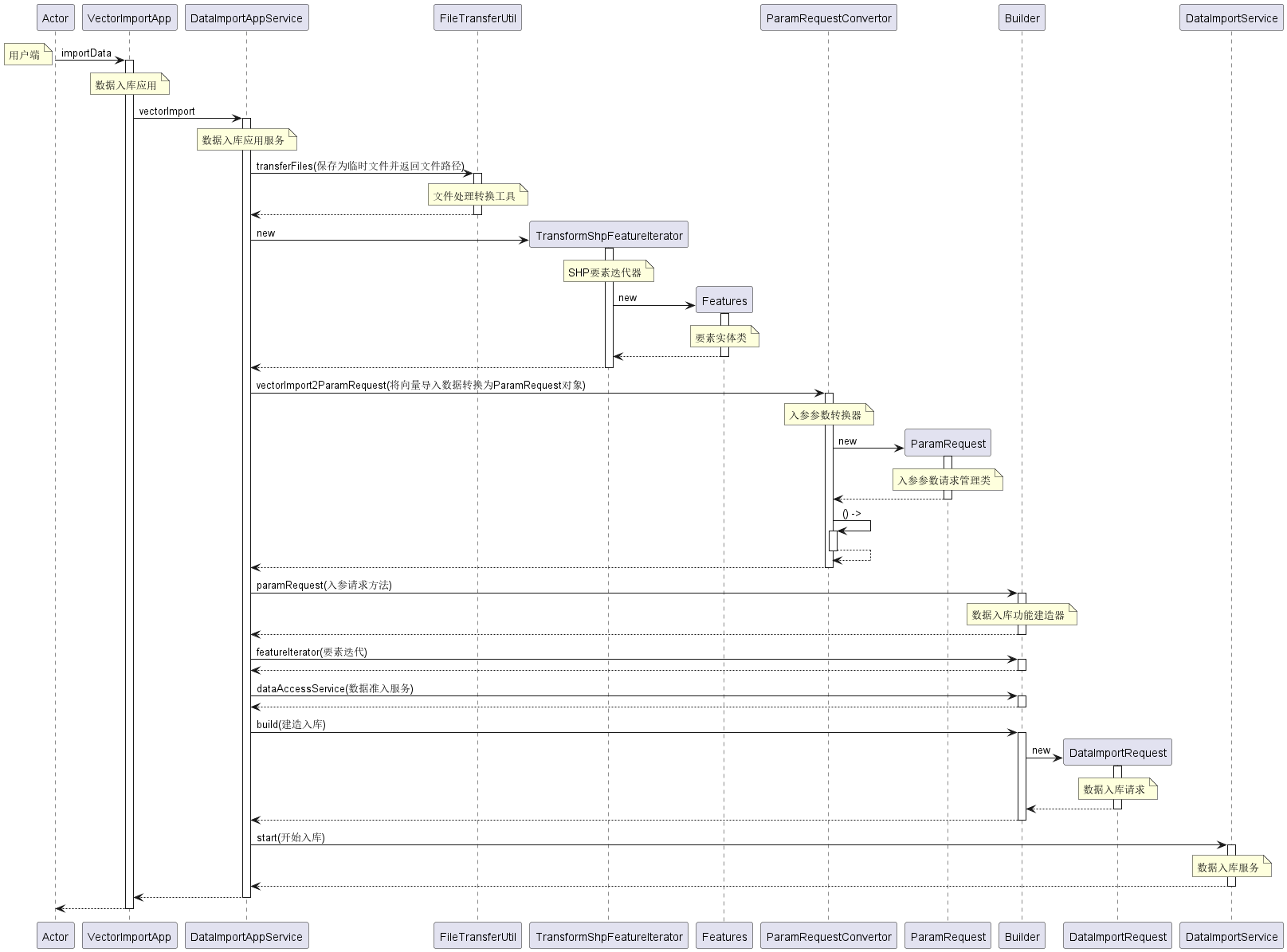
下图是Shapefile矢量文件的数据入库时序图,通过该图,我们可以很清晰地看出要扩展更多不同格式(csv,json等)的数据入库功能需要经过哪些具体的步骤。可以看到DataImportService的start方法启动了数据入库服务。在这之前,所有的工作都为start方法作准备。其中最重要的准备工作是实现FeatureIterator接口(下图中实现该接口的类是ShpFeatureIterator),然后通过建造者Builder类注入FeatureIterator接口的具体实现。
通过这个过程的我们可以发现,核心组件(cmp)被完全解耦,并没有直接出现在时序图中。这正是符合了我们预期的设计思想,数据入库底层逻辑与数据不再强耦合,也尽量确保了每个模块和类都遵循单一职责原则。除此之外,我们可以看到,我们使用了一些接口和抽象来定义模块之间的契约。更容易地进行替换或扩展。
时序图
如何拓展其他格式数据文件的入库
在我们的网格码引擎项目中,我们设计了一个自定义迭代器迭代要素的思想,在我们的要素迭代器设计理念中,无论什么格式的矢量文件,通过要素迭代器都可以提供一个个要素给到客户端,客户端针对得到的要素进行相关处理再入库。
那么,要素迭代器如何才能提供要素给客户端呢,这就涉及到要素迭代器的底层设计,底层设计中我们抽象了一个名为FeatureIterator的接口定义,而该接口是继承扩展了 Java 的 Iterator 接口得来。
以最常见的shp格式的矢量文件入库为例,如果我们需要用要素迭代器设计思想得到一个个要素,那么我们需要实现一个矢量数据迭代器,命名为ShpFeatureIterator。矢量数据迭代器接收一个后缀名为.shp的文件,矢量在迭代器中通过特定的逻辑处理,得到一个个要素。
理清了要素迭代器的思想后,如何拓展其他格式数据文件的入库呢?如果有一个csv格式的文件,那么我们只需要实现FeatureIterator接口的csv数据迭代器,然后再提供要素给客户端使用。
数据入库核心组件
数据入库核心组件由如下流程组成。包括接口入参组件、数据准入组件、索引覆盖组件、要素提取器组件、网格编码组件、nlp自然语言组件、SpEL数据增强组件、存储组件、 日志更新组件。
接口入参组件-ParamCmp
为了让Liteflow工作流引擎将整个数据入库流程串联起来,需要设置必要的参数贯穿始终。该组件的目的是把数据入库必备的参数包装成DDD领域中的贫血模型,并将该贫血模型存入流程引擎上下文。
1// 包装成接口入参贫血对象 2Param param = new Param.Builder() 3 .task_id(new TaskID(requestData.getParamRequest().getTaskId())) 4 .index_library_name(indexLibraryNameFactory.create(requestData.getParamRequest().getIndex_library_name())) 5 .table_name(requestData.getParamRequest().getTable_name()) 6 .big_table_name(requestData.getParamRequest().getBig_table_name()) 7 .geo_level(new Geolevel(requestData.getParamRequest().getGeo_level())) 8 .cover_data(requestData.getParamRequest().getCover_data()) 9 .flatten_2d(requestData.getParamRequest().getFlatten_2d()) 10 .nlp(nlpFactory.create(requestData.getParamRequest().getNlp())) 11 .expression(new Expression(requestData.getParamRequest().getExpression())) 12 .build(); 13 // 存入数据入库流程上下文 14context.setParam(param);
这种设计方式相比传统的直接参数传递模式,极大地简化了参数管理和数据传递的复杂性。
数据准入组件-DataAccessCmp
这个组件的主要目的是判断数据是否准入。若一份矢量数据不符合入库标准,则在该阶段直接拒绝进入数据入库流程,或进行用户提示处理,表示只有符合哪些条件的数据才会被执行打码入库。
DataAccessCmp组件起到一个数据是否进行入库的门卫角色,只有当DataAccessService的data_access方法返回true时,才允许数据的访问。DataAccessCmp组件负责将第三方系统实现好的数据准入接口功能注入到数据入库流程内,由下图红色方框所示。
package com.zkyy.sandbox.facade.access;
/**
* 数据准入接口,交给外部实现后注入到框架内
*/
public interface IDataAccessService {
Boolean data_access(); // 是否准入
}
索引覆盖组件-CoverDataCmp
有时一份要入库的矢量数据过于庞大,或将多份数据存储到同一个索引中,则必须设置为数据“追加”模式;否则执行数据“删除”模式。该组件的作用在于若为“删除”模式时,执行索引删除操作;若为数据“追加”模式时,则执行索引映射更新操作,以保证追加的数据能以正确的数据结构存储入库。
1 // 是否需要覆盖原索引 2Boolean coverData = context.getParam().getCover_data(); 3 if (coverData) { 4 // 删除模式 5 IndexManagementUtils.deleteIndex(......); 6 // 创建映射(如果开启了自然语言,则按照自然语言创建映射,否则就按照字段创建映射) 7 ...... 8 } else { 9 // 追加模式 10 if (IndexManagementUtils.indexExist(......) { 11 //索引存在,更新映射 12 ...... 13 //索引不存在,构建新映射 14 ...... 15 } 16
要素提取组件-FeatureIteratorCmp
FeatureIteratorCmp 组件提供了一种机制,用于迭代提取要素。处理大量数据时,我们可以一次处理一个要素,而不是一次性加载所有要素。该组件必须要由第三方实现FeatureIterator接口,接口定义如下:
1public interface FeatureIterator extends Iterator{ 2 3 boolean hasNext() ; // 是否存在下一个要素 4 5 Features next(); // 获得下一个要素 6 7 void init(); // 将iterator初始化,将迭代器的指针指向第一个要素 8 9 Features getFeature(); // 获得Features实体 10 11 Long size(); // 迭代器中要素的总数 12 13} 14
网格编码组件-GeosotCmp
GeosotCmp 组件负责计算网格编码。
自然语言组件-NlpCmp
自然语言组件用于提高模糊检索效率,对接Python模型组件(外部系统)。
接口调用示例,该功能是从poi索引大表中搜索属性为NAME近似于“保险”的相关数据。
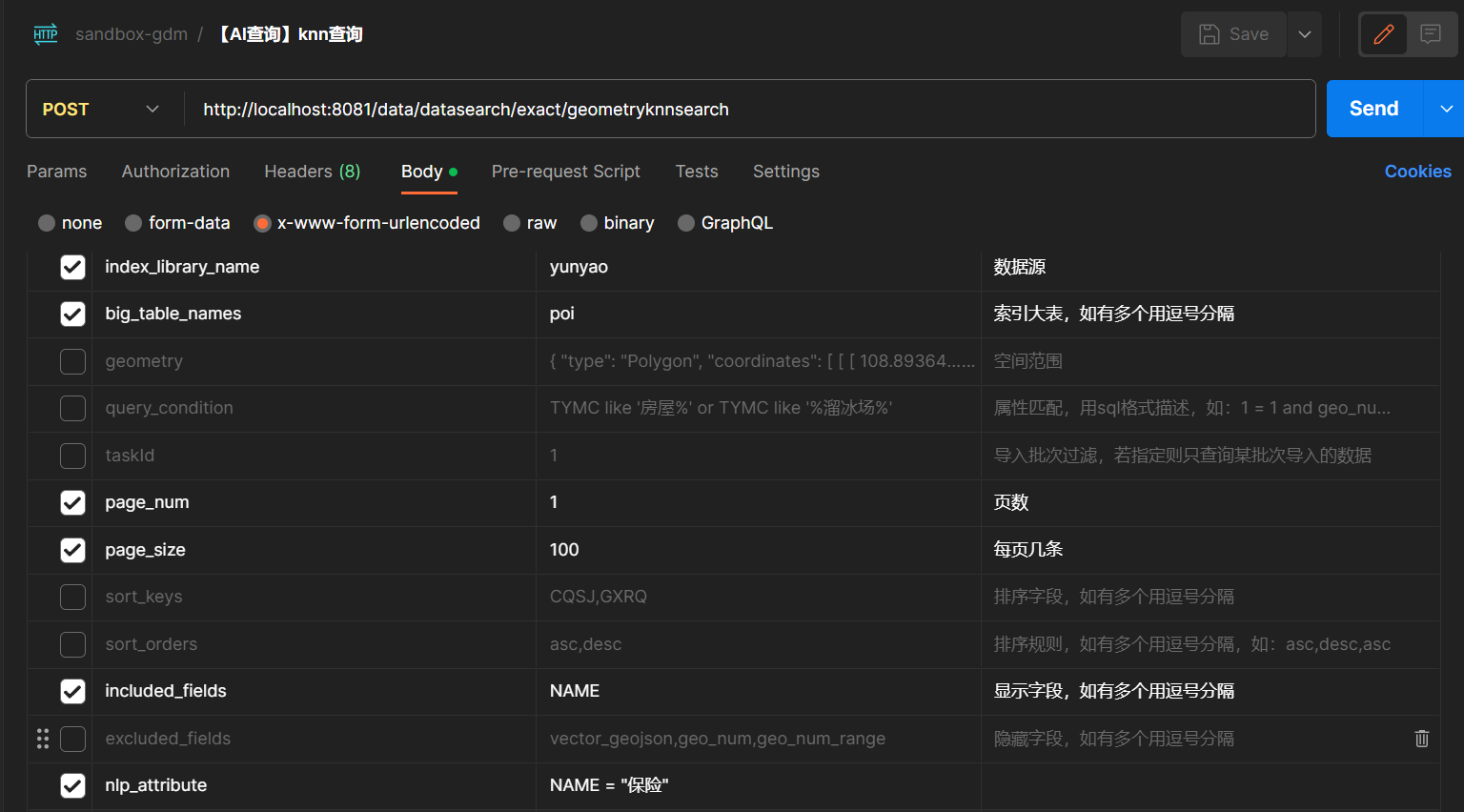
数据增强组件-SpELCmp

数据存储组件-DataStoreCmp
该组件的作用是将数据批量入库,并将存储结果维护和更新导入日志——当数据入库发生错误时,该组件会维护一份日志信息实体,最后会由数据导入日志组件DataStoreCmp进行处理。
-
批量处理和存储数据:
DataStoreCmp组件可以批量处理和存储数据,这可以大大提高数据入库效率。 -
维护和更新导入日志:
DataStoreCmp组件在批量数据入库过程中,会持续维护和更新导入日志,这对于跟踪数据导入的过程和状态,以及后期的问题排查都非常重要。
数据导入日志组件-ImportLogCmp
这个组件的主要目的是在数据导入过程中更新日志。它首先创建新的日志记录,然后在数据导入过程中根据入库进度动态更新日志,最后在数据导入完成后再次更新日志并重置状态。

意义
-
跟踪数据导入的进程:通过
ImportLogCmp组件,开发者可以清晰地了解到数据导入过程的每一个阶段,这对于理解和控制数据导入的过程非常有帮助。 -
避免频繁的IO操作:
ImportLogCmp组件在更新日志时,只有当进度发生变化时才会进行,这避免了频繁的IO操作,从而提高了性能。 -
方便问题排查:如果数据导入过程中出现问题,开发者可以通过查看
ImportLogCmp组件创建的日志,快速定位并解决问题。
结束流程组件-endCmp
EndCmp是一个简单的Liteflow组件,它的主要目的是在流程结束时打印一个日志信息。这个组件并不包含任何复杂的逻辑。
🍊 数据检索
2.1 空间检索
2.1.1 精确拓扑检索
介绍
相比于网格码检索,精确拓扑检索是一种更准确的空间数据检索方法,不会带来网格存在的误差。
示例
精确拓扑检索功能调用时序图
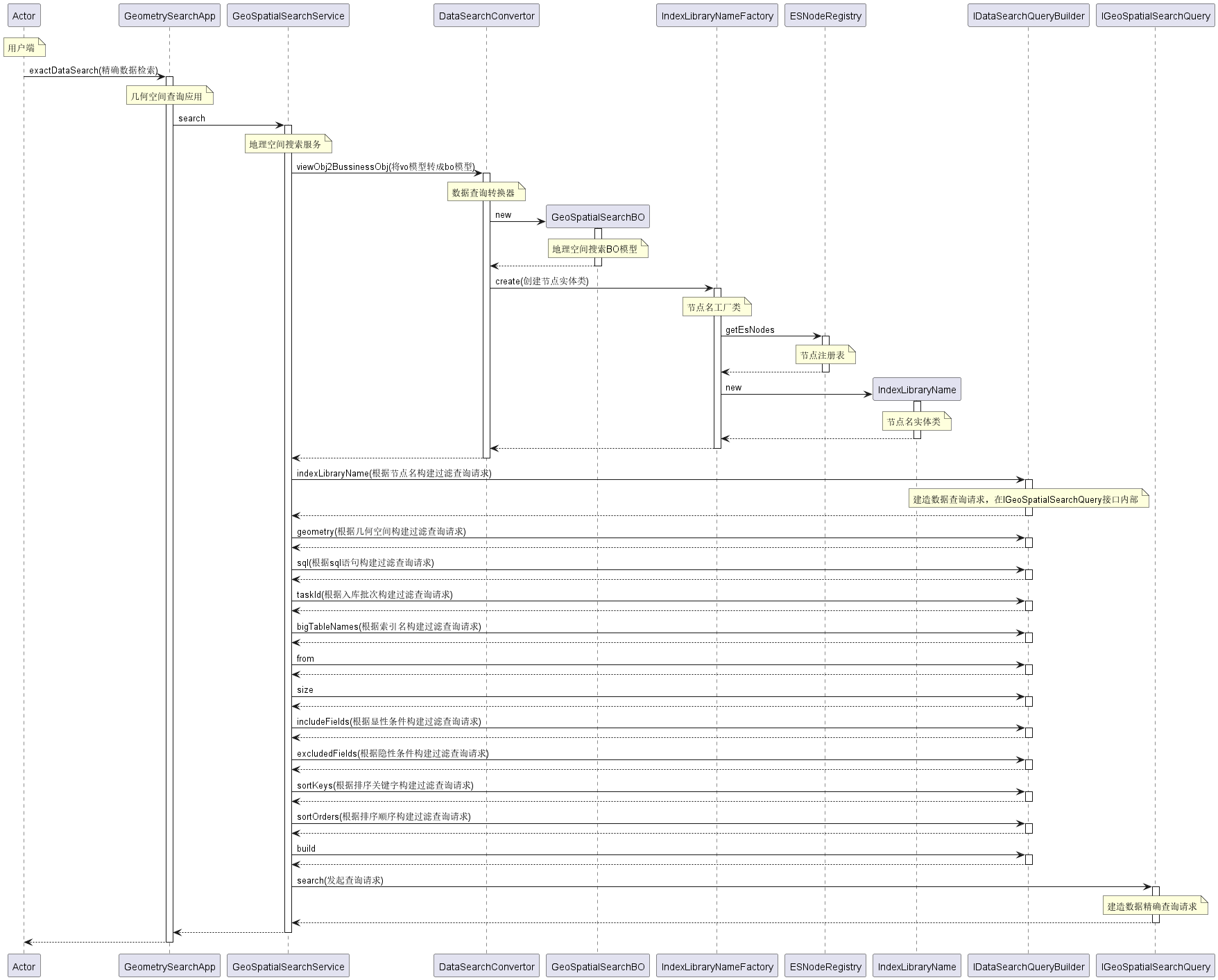
代码
1@Service 2public class GeoSpatialSearchService { 3 @Resource 4 private IndexLibraryNameFactory indexLibraryNameFactory; 5 @Resource 6 private IGeoSpatialSearchQuery.IDataSearchQueryBuilder dataSearchQueryBuilder; 7 /** 8 * 数据查询 9 * @param request DataSearchRequest数据查询请求类 10 * @param tClass 反序列化类 11 * @return 12 * @param <T> 13 * @throws IOException 14 */ 15 public <T> DataSearchResponseVO<T> search(GeoSpatialSearchRequestVO request, Class<T> tClass) throws IOException { 16 // 将vo模型转成bo模型 17 GeoSpatialSearchBO geoSpatialSearchBO = DataSearchConvertor.viewObj2BussinessObj(request, indexLibraryNameFactory); 18 // 构建空间数据查询请求 19 IGeoSpatialSearchQuery dataSearchQuery = dataSearchQueryBuilder 20 .indexLibraryName(geoSpatialSearchBO.getIndex_library_name()) 21 .geometry(geoSpatialSearchBO.getGeometry()) 22 .sql(geoSpatialSearchBO.getQuery_condition()) 23 .taskId(geoSpatialSearchBO.getTaskId()) 24 .bigTableNames(geoSpatialSearchBO.getBig_table_names()) 25 .from(geoSpatialSearchBO.getFrom()) 26 .size(geoSpatialSearchBO.getSize()) 27 .includeFields(geoSpatialSearchBO.getIncluded_fields()) 28 .excludedFields(geoSpatialSearchBO.getExcluded_fields()) 29 .sortKeys(geoSpatialSearchBO.getSort_keys()) 30 .sortOrders(geoSpatialSearchBO.getSort_orders()) 31 .build(); 32 // 发起查询请求 33 DataSearchResponseVO<T> dataSearchResponseVO = dataSearchQuery.search(tClass); 34 return dataSearchResponseVO; 35 }
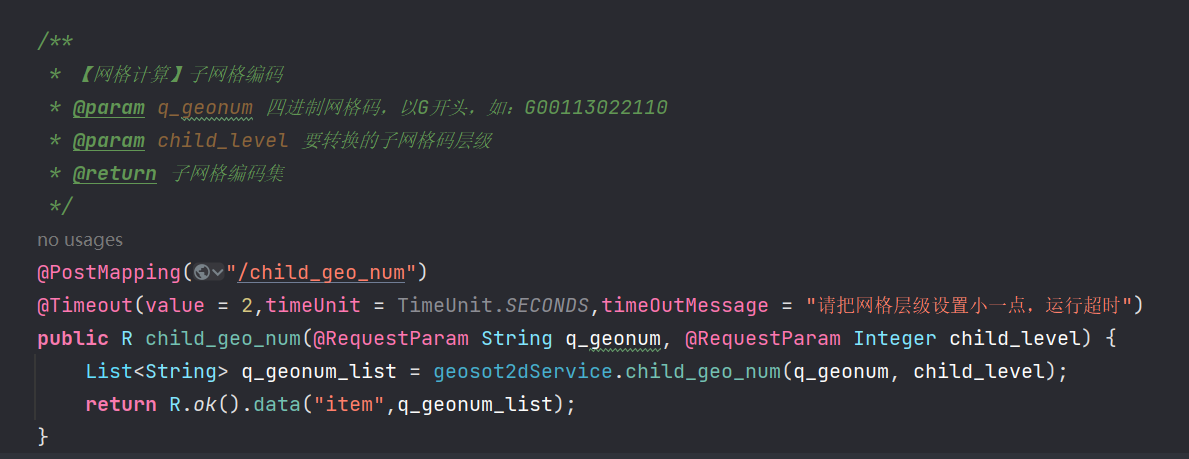
2.1.2 网格编码检索
介绍
网格编码检索是一种特殊类型的空间数据检索,它利用网格编码来定位和检索地理空间数据,充分利用ELasticsearch倒排索引的特性,检索数据贼快,但网格编码过程较慢,还会带来一定的我网格误差。
示例
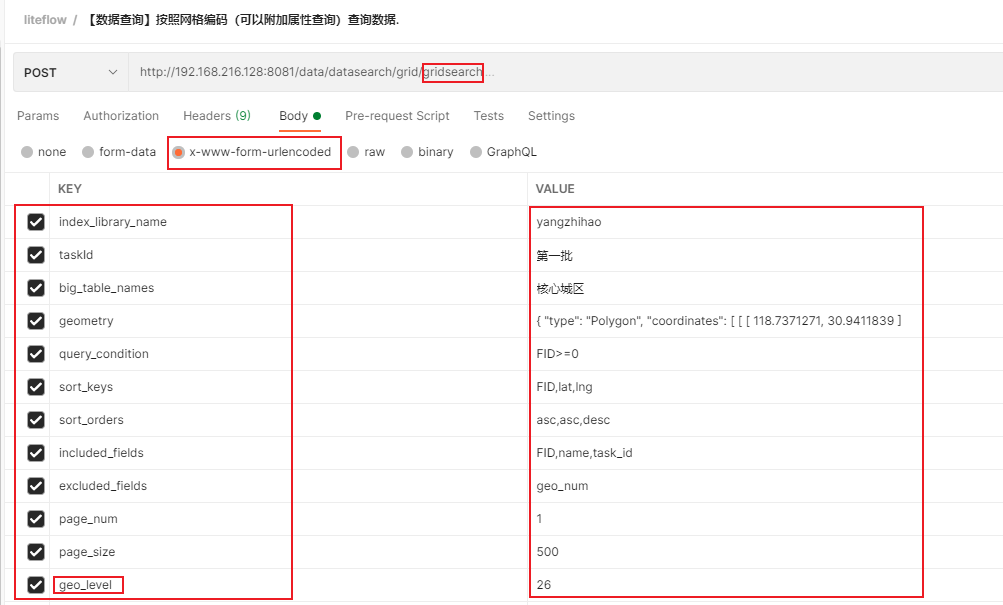
时序图
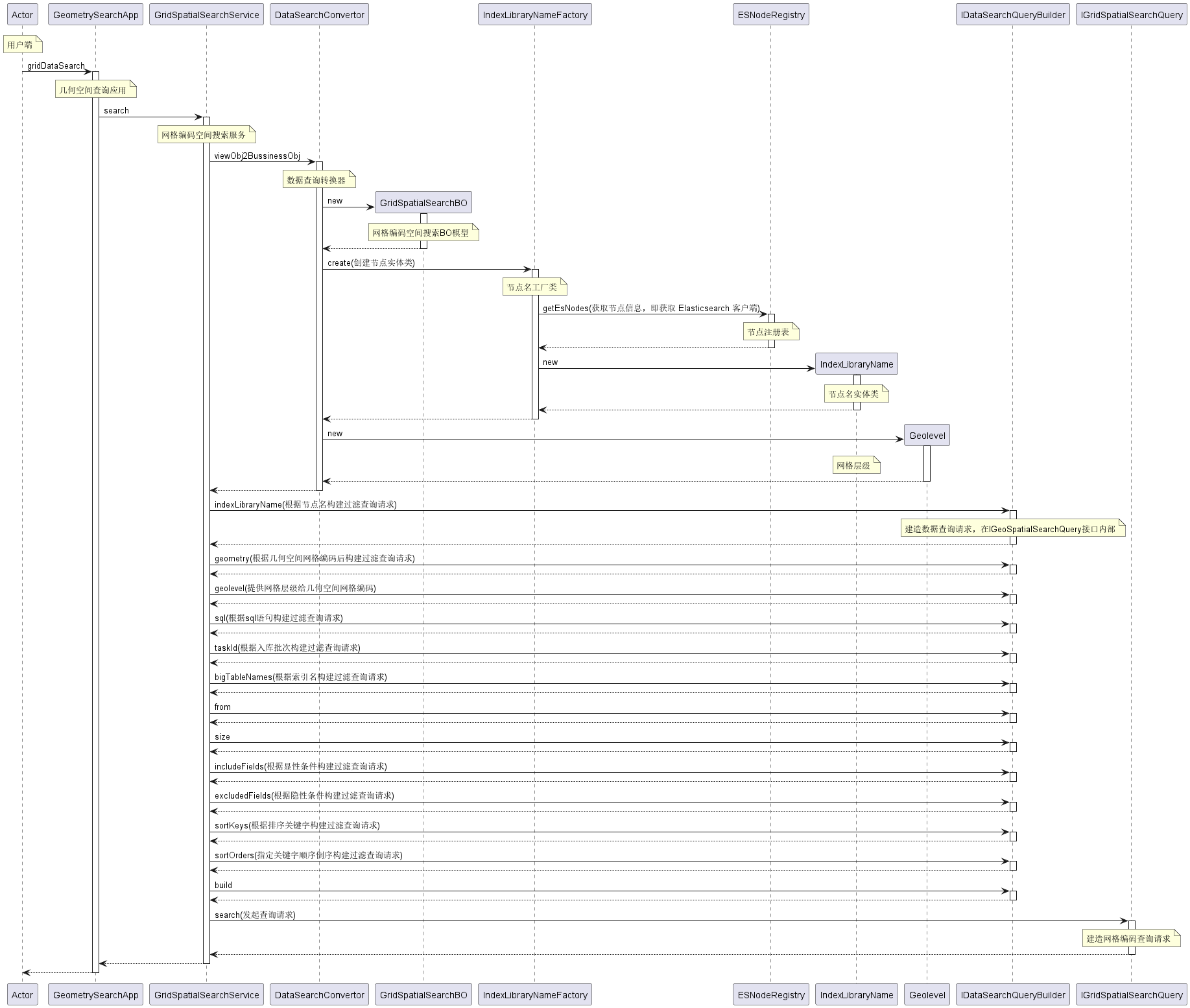
代码
1@Service 2public class GridSpatialSearchService { 3 @Resource 4 private IndexLibraryNameFactory indexLibraryNameFactory; 5 @Resource 6 private IGridSpatialSearchQuery.IDataSearchQueryBuilder dataSearchQueryBuilder; 7 public <T>DataSearchResponseVO<T> search(GridSpatialSearchRequestVO requestVO,Class<T> tClass) throws IOException{ 8 // 将vo模型转成bo模型 9 GridSpatialSearchBO gridSpatialSearchBO = DataSearchConvertor.viewObj2BussinessObj(requestVO, indexLibraryNameFactory); 10 // 构建网格数据查询请求 11 IGridSpatialSearchQuery iGridSpatialSearchQuery = dataSearchQueryBuilder 12 .indexLibraryName(gridSpatialSearchBO.getIndex_library_name()) 13 .geometry(gridSpatialSearchBO.getGeometry()) 14 .geolevel(gridSpatialSearchBO.getGeolevel()) 15 .sql(gridSpatialSearchBO.getQuery_condition()) 16 .taskId(gridSpatialSearchBO.getTaskId()) 17 .bigTableNames(gridSpatialSearchBO.getBig_table_names()) 18 .from(gridSpatialSearchBO.getFrom()) 19 .size(gridSpatialSearchBO.getSize()) 20 .includeFields(gridSpatialSearchBO.getIncluded_fields()) 21 .excludedFields(gridSpatialSearchBO.getExcluded_fields()) 22 .sortKeys(gridSpatialSearchBO.getSort_keys()) 23 .sortOrders(gridSpatialSearchBO.getSort_orders()) 24 .build(); 25 // 执行查询请求 26 return iGridSpatialSearchQuery.search(tClass); 27 } 28}
2.2属性检索
2.2.1 自然语言检索
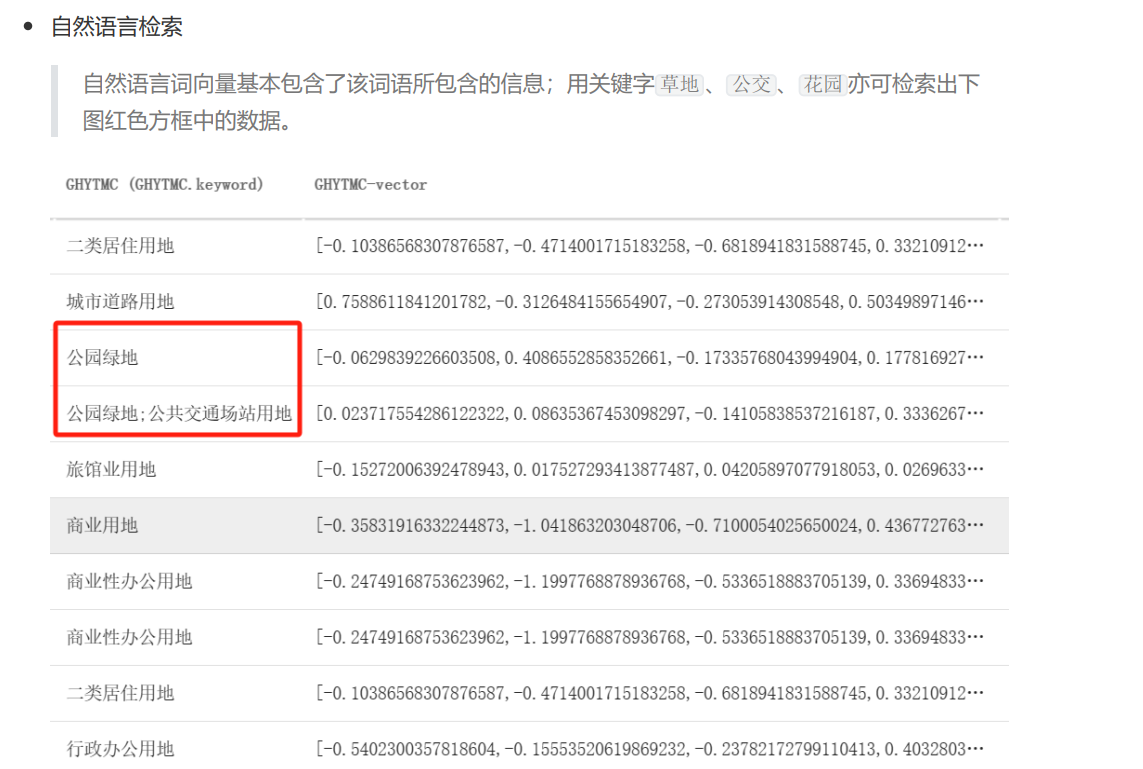
2.2.2 属性检索
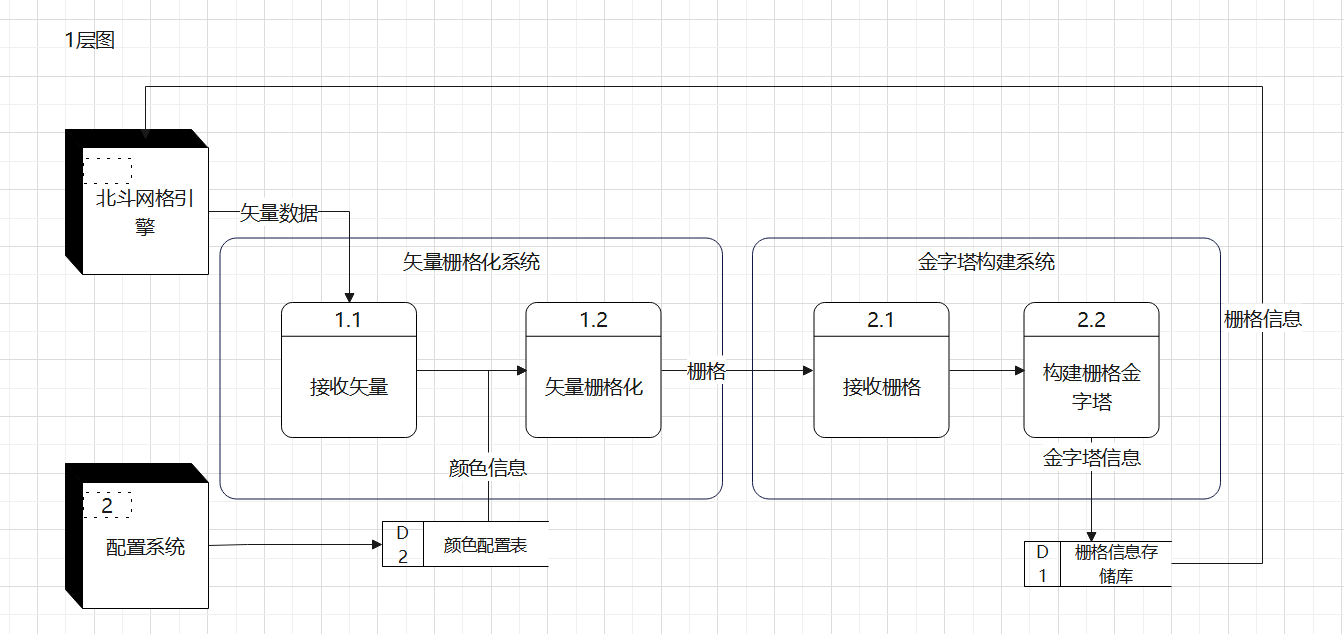
2.3 栅格检索
为了解决大批量矢量数据加载到前端页面时发生的卡顿问题,新增了一个外部系统用于构建图像金字塔,下图是外部系统的数据流图。对于北斗网格引擎来说,只有一个扇入和扇出。该功能正在开发中。
🥝 节点管理
3.1 什么是节点注册表
节点注册表可以帮助我们查找和管理所有已注册的节点(即index_library_name)。在Spring Boot项目启动时,提供了一个自动在的bean注入完成后执行的初始化方法,用于生成节点注册表。
这个初始化方法initESNode通过从数据源中读取所有的节点数据,尝试与每个节点建立连接,并将成功连接的节点信息存入到节点注册表中。如果连接到某个节点失败,将更新该节点的状态为未连接,并生成一条错误日志。如果连接成功,将更新该节点的状态为已连接。
以下是initESNode的主要步骤:
- 从数据源中读取所有节点的数据。
- 对每个节点执行以下操作:
- 尝试与节点建立连接。
- 如果连接成功,将节点信息存入节点注册表,并更新节点的状态为已连接。
- 如果连接失败,更新节点的状态为未连接,并生成一条错误日志。
- 生成一条信息日志,表示节点数据已存入注册表。
示例

底层逻辑
1/** 2 * 在springboot的bean注入完成后,自动执行该初始化方法,将节点数据存入注册表中 3 * 4 * @throws Exception 5 */ 6@PostConstruct 7public void initESNode() throws Exception { 8 // 从data_sources中读取数据 9 List<DataSourceDO> dataSourceDOList = dataSourceRepository.findAll(); 10 for (DataSourceDO dataSourceDO : dataSourceDOList) { 11 try { 12 // 检测是否连通,加入注册表 13 ElasticsearchClient node = checkConnected(dataSourceDO.getNodes().getIp().getIp(), dataSourceDO.getNodes().getPort().getPort(), 14 dataSourceDO.getNodes().getUsername().getUsername(), dataSourceDO.getNodes().getPassword().getPassword(), dataSourceDO.getNodes().getScheme().getScheme()); 15 this.esNodes.put(dataSourceDO.getIndex_library_name(), node); 16 //节点连接成功,更改节点连接状态为 true 17 this.dataSourceRepository.statusChange(dataSourceDO.getIndex_library_name(), true); 18 } catch (ESNodeConnectException e) { 19 //节点连接失败,更改节点连接状态为 false 20 this.dataSourceRepository.statusChange(dataSourceDO.getIndex_library_name(), false); 21 log.error("无法连接到节点: " + dataSourceDO.getNodes().getIp().getIp() + ":" + dataSourceDO.getNodes().getPort().getPort()+" 节点名:"+dataSourceDO.getIndex_library_name()); 22 } 23 } 24 log.info("节点数据存入注册表-完成"); 25}
3.2 节点注册
介绍
节点注册提供了一种方便和有效的方式,能够动态地扩展 Elasticsearch 集群,以及为这些新加入的节点提供管理和跟踪功能。
设计理念
当需要动态地添加或删除集群节点。addEsNode 方法使得开发者能够轻松地将新的 Elasticsearch 节点注册到集群中,而无需手动修改配置文件或重启服务。这种动态扩展的能力可以大大提高系统的灵活性和适应性。
用意
- 动态添加节点:
addEsNode方法允许开发者在运行时添加新的 Elasticsearch 节点。这可以是为了扩大集群的处理能力,或者是为了增加集群的冗余度以提高可用性。 - 连接状态检查:在添加新节点时,
addEsNode方法会首先检查新节点的连接状态。这是为了确保新节点是可用的,以防止添加无效的节点。 - 持久化节点信息:
addEsNode方法还会在数据源中存储新节点的信息,这是为了在服务重启时能够恢复节点状态。这种持久化的能力可以提高系统的可靠性。 - 异常处理:如果新节点不能连接,
addEsNode方法会抛出异常。这可以让调用者知道添加节点操作的结果,从而可以根据需要进行错误处理。
时序图(附中文注释)
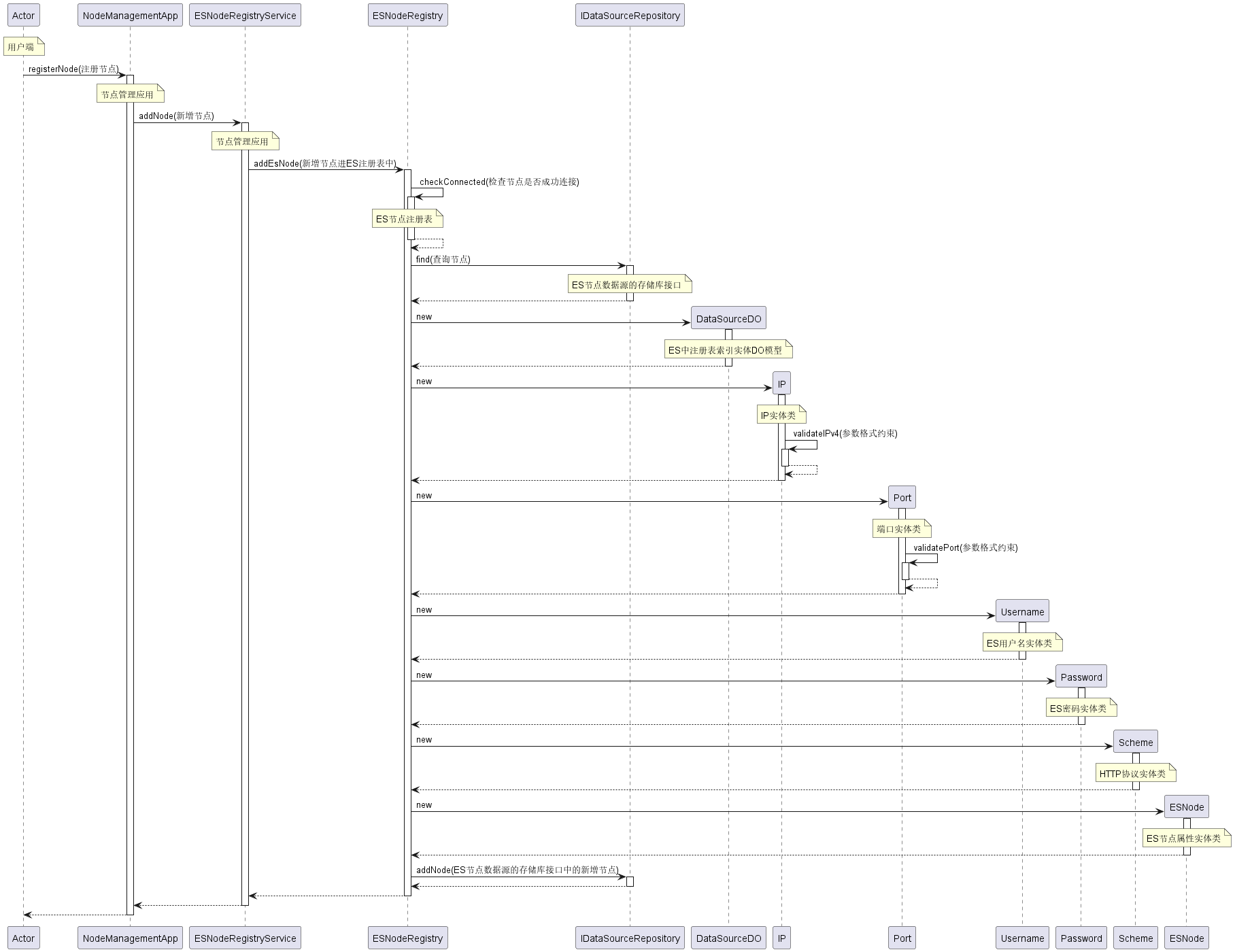
使用
1private ESNodeRegistryService esNodeRegistryService; 2esNodeRegistryService.addNode(index_library_name, ip, port, username, password,scheme);
示例
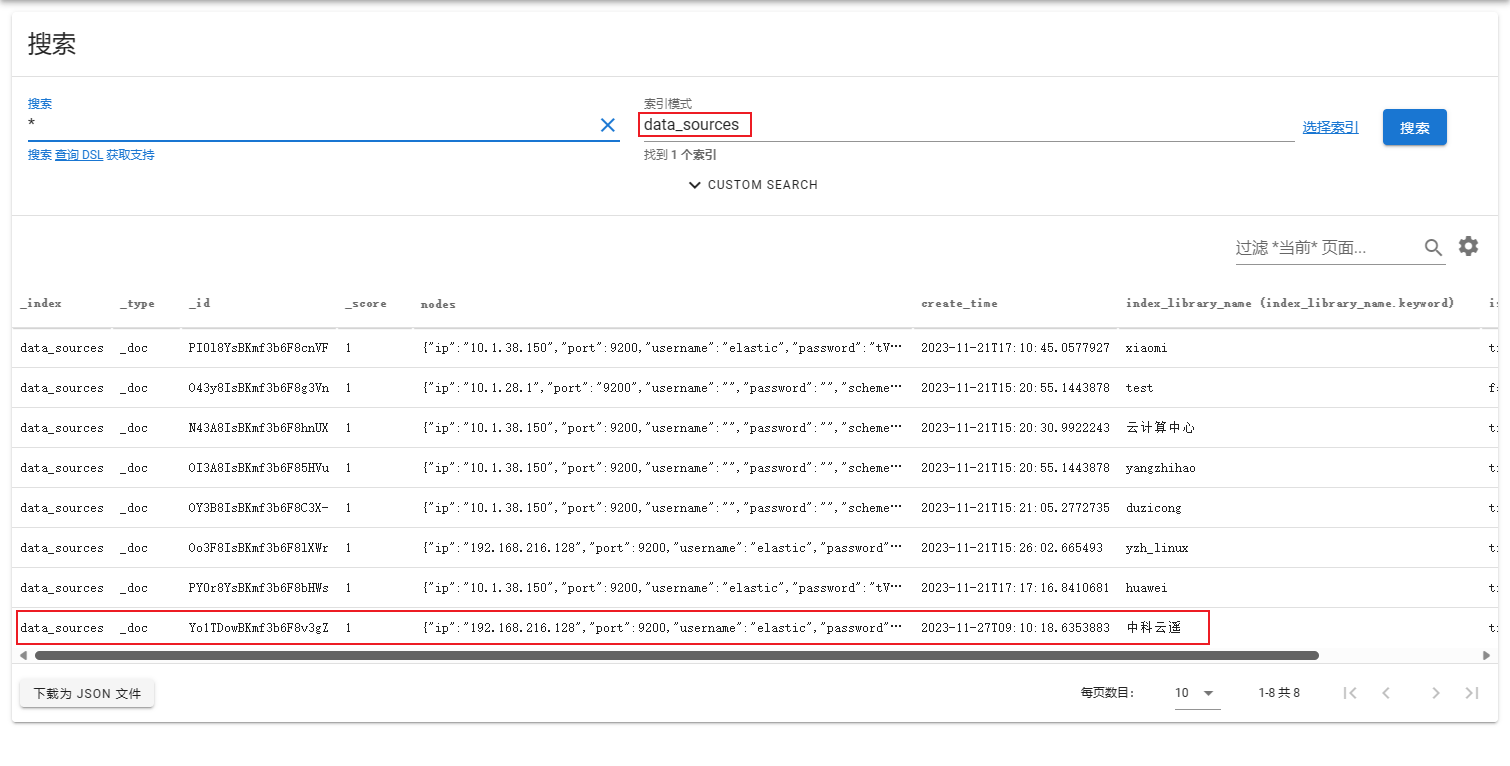
底层逻辑
1public Map<String, ElasticsearchClient> addEsNode(String index_library_name, String ip, Integer port, String username, String password, String scheme) { 2 // 检测网络是否通畅 3 ElasticsearchClient client = checkConnected(ip, port, username, password, scheme); 4 try { 5 if (this.esNodes.containsKey(index_library_name) && this.dataSourceRepository.find(index_library_name).getIs_connected()) { 6 // 如果原先索引源存在,且is_connected字段为true则不能注册 7 throw new ESNodeConnectException(String.format("无法新增节点,%s索引源已存在,ip为:%s,port为:%d", index_library_name, ip, port)); 8 } 9 } catch (ElasticsearchException e) { 10 throw new ESNodeConnectException("该节点连接失败,无法新增节点" + e.getMessage()); 11 } 12 this.esNodes.put(index_library_name, client); // 注册表添加节点 13 DataSourceDO dataSourceDO = new DataSourceDO(); 14 dataSourceDO.setNodes(new ESNode(new IP(ip), new Port(port), new Username(username), new Password(password), new Scheme(scheme))); 15 dataSourceDO.setIs_connected(true); 16 dataSourceDO.setCreate_time(new Date()); 17 dataSourceDO.setIndex_library_name(index_library_name); 18 this.dataSourceRepository.addNode(dataSourceDO); // 写入持久化层 19 return this.esNodes; 20}
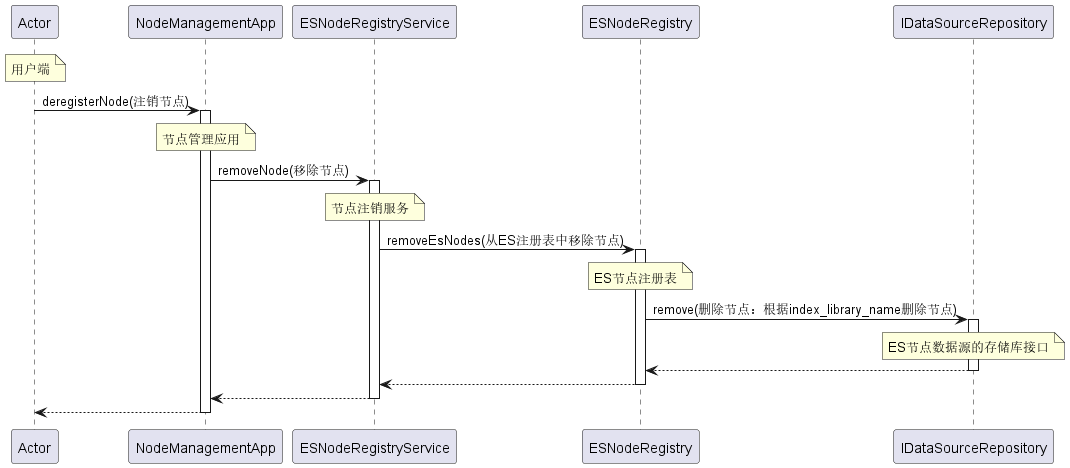
3.3 节点注销
介绍
在 Elasticsearch 集群管理中,不仅需要能够动态添加节点,还需要能够在不再需要特定节点的时候将其注销。removeNode 方法就是为了实现这个目的而设计的。这个方法提供了一种方便的方式来注销并删除注册表中的 Elasticsearch 节点。
时序图(附中文注释)
使用
1private ESNodeRegistryService esNodeRegistryService; 2esNodeRegistryService.removeNode(index_library_name);
示例
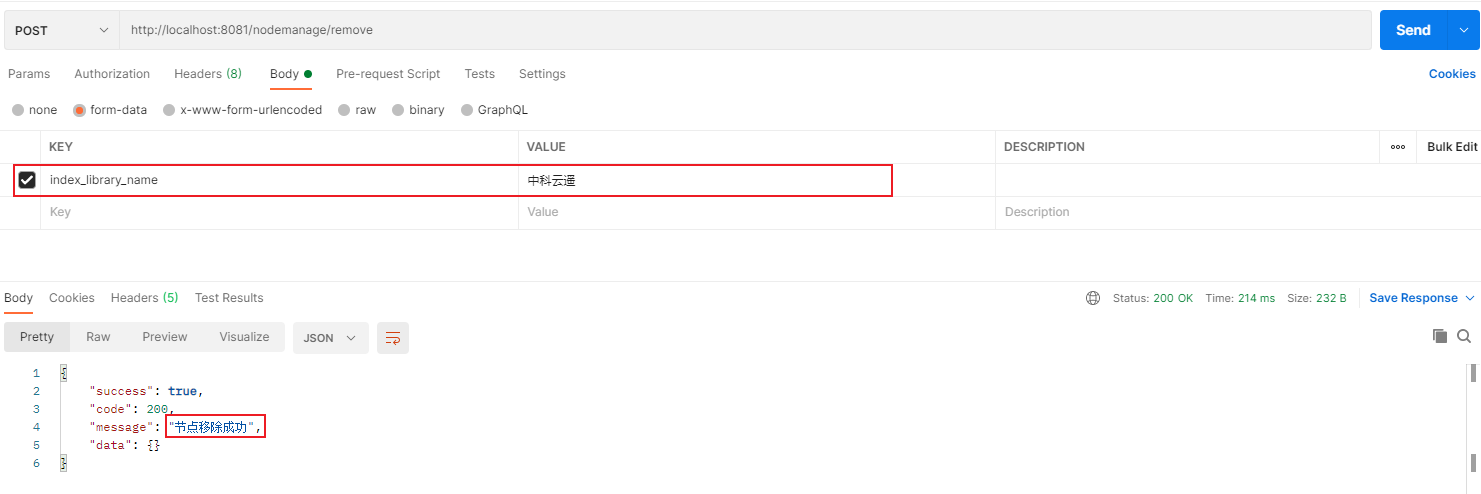
底层逻辑
1public Boolean removeEsNodes(String index_library_name) { 2 // 从注册表中删除 3 ElasticsearchClient removeESClient = this.esNodes.remove(index_library_name); 4 if (removeESClient == null) { 5 throw new ESNodeNotFoundException(index_library_name + "对应ES节点不存在于注册表中,无需删除"); 6 } 7 // 从持久层中删除 8 Boolean removeSuccess = dataSourceRepository.remove(index_library_name); 9 if (removeSuccess) { 10 return true; 11 } 12 return false; 13}
基础
🍍 YML配置文件
配置临时文件夹路径
介绍
这个配置application.tempFolderPath: D:\\temp 在我的Spring Boot应用程序中设定了一个临时文件夹的路径。这个路径用于存储应用程序产生的临时文件。
使用
在我们的应用程序中,我们使用以下配置来设定一个临时文件夹的路径:
1application: 2 tempFolderPath: D:\\temp
注:在项目启动前需手动创建一个temp临时文件夹,并根据路径修改配置文件。
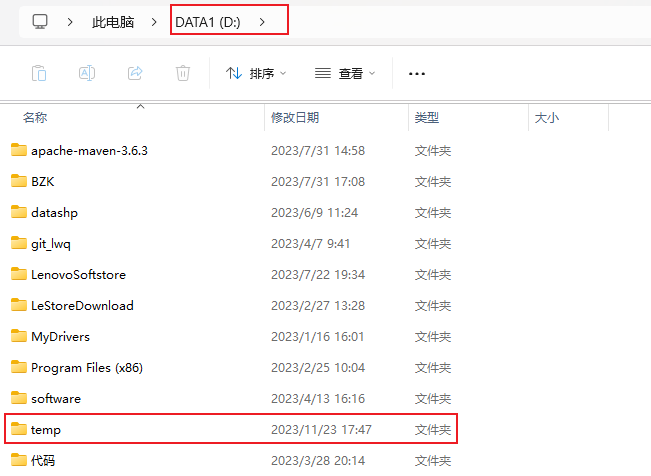
更改
你可以根据你的需要修改这个配置。例如,如果你想要将临时文件夹改为 D:\myapp\temp,你可以改为:
1application: 2 tempFolderPath: D:\\myapp\\temp
配置Elasticsearch和文件上传限制
介绍
在我们的系统设计中,必须要包括一个ELasticsearch主节点,该节点的data_source索引中记录了各个逻辑节点的连接方式。
使用
ELasticsearch主节点配置。包括Elasticsearch服务器的地址(host)、端口(port)、协议(scheme)、用户名(username)和密码(password)。
1spring: 2 data: 3 elasticsearch: 4 rest: 5 port: 9200 6 scheme: https 7 host: 10.1.38.150 8 username: elastic 9 password: flcl*YZwflctpCnTFGKI
文件上传限制配置
此外,我们还设置了文件上传的大小限制。在这个配置中,我们设置了单个文件的最大大小(max-file-size)和一个请求中所有文件的总大小(max-request-size)均为100MB。
1spring: 2 servlet: 3 multipart: 4 max-file-size: 100MB 5 max-request-size: 100MB
配置自然语言nlp词向量服务
介绍
在我们的应用程序中,我们使用一个特定的服务来将自然语言转换为向量表示
使用
1custom: 2 url: "http://10.1.36.173:5000"
配置LiteFlow 规则源文件
介绍
在我们的应用程序中,我们使用LiteFlow框架来组织和执行复杂的业务逻辑。
使用
1liteflow: 2 rule-source: config/flow.el.xml
这个配置项告诉LiteFlow框架,应该从哪个文件中加载业务流程规则。在这个例子中,应用程序将从config/flow.el.xml文件中加载规则。
注:请确保你设定的文件路径正确指向了你的规则源文件,否则LiteFlow可能无法正确加载和执行规则。
flow.el.xml文件参考:
1<?xml version="1.0" encoding="UTF-8"?> 2<flow> 3 <!-- 数据入库 --> 4 <chain name="dataImportChain"> 5 THEN( 6 param, 7 dataAccessChain 8 ); 9 </chain> 10 <!-- 数据不准入就退出,否则进入编码流程 --> 11 <chain name="dataAccessChain"> 12 IF(dataAccess,mainChain); 13 </chain> 14 <!-- 编码流程,索引覆盖组件、网格编码组件、存储组件、日志组件 --> 15 <chain name="mainChain"> 16 THEN( 17 coverData, 18 WHILE(featureIterator).DO( 19 THEN( 20 WHEN(geosot,nlp,SpelCmp).maxWaitSeconds(10000), 21 dataStore, 22 importLog 23 ) 24 ) 25 ); 26 </chain> 27</flow>
🍇 POM配置文件
开发环境
我们基于Java17、Spring Boot 2.5.5、ELasticsearch8.8.2 开发了本项目。
1<properties> 2 <java.version>17</java.version> 3 <spring.boot.version>2.5.5</spring.boot.version> 4 <elasticsearch.version>8.8.2</elasticsearch.version> 5</properties>
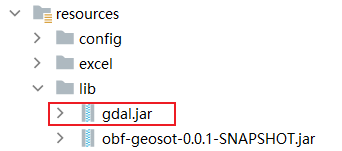
必备的第三方包依赖
1<!--gdal--> 2<dependency> 3 <groupId>org.gdal</groupId> 4 <artifactId>gdal</artifactId> 5 <version>1.0.0</version> 6 <scope>system</scope> 7 <systemPath>${pom.basedir}/src/main/resources/lib/gdal.jar</systemPath> 8</dependency>
1<!-- 自研网格编码算法包 --> 2<dependency> 3 <groupId>com.zkyy.duzicong</groupId> 4 <artifactId>geosot</artifactId> 5 <version>1.0.0</version> 6 <scope>system</scope> 7 <systemPath>${pom.basedir}/src/main/resources/lib/obf-geosot-0.0.1-SNAPSHOT.jar</systemPath> 8</dependency>
1<!-- geotools包 --> 2<dependency> 3 <groupId>org.geotools</groupId> 4 <artifactId>gt-shapefile</artifactId> 5 <version>25.5</version> 6</dependency> 7<dependency> 8 <groupId>org.geotools</groupId> 9 <artifactId>gt-swing</artifactId> 10 <version>25.5</version> 11</dependency> 12<dependency> 13 <groupId>org.geotools</groupId> 14 <artifactId>gt-geojson</artifactId> 15 <version>25.5</version> 16</dependency> 17<dependency> 18 <groupId>org.geotools</groupId> 19 <artifactId>gt-main</artifactId> 20 <version>25.5</version> 21</dependency> 22<dependency> 23 <groupId>org.geotools</groupId> 24 <artifactId>gt-epsg-hsql</artifactId> 25 <version>25.5</version> 26</dependency> 27<dependency> 28 <groupId>org.geotools</groupId> 29 <artifactId>gt-geotiff</artifactId> 30 <version>25.5</version> 31</dependency>
配置 build
1<build> 2 <plugins> 3 <plugin> 4 <groupId>org.springframework.boot</groupId> 5 <artifactId>spring-boot-maven-plugin</artifactId> 6 <executions> 7 <execution> 8 <goals> 9 <goal>repackage</goal> 10 </goals> 11 </execution> 12 </executions> 13 <configuration> 14 <includeSystemScope>true</includeSystemScope> 15 </configuration> 16 </plugin> 17 </plugins> 18 <resources> 19 <resource> 20 <directory>src/main/resources</directory> 21 <includes> 22 <include>**/*.yml</include> 23 <include>**/*.xml</include> 24 <include>validate.txt</include> 25 <include>public.txt</include> 26 </includes> 27 </resource> 28 </resources> 29</build>
注:public.txt和validate.txt这两个文档请放在src/main/resources中,这样通过maven打包才能打包在同一个文件夹中识别到。
注:由于自研算法包指定了public.txt和validate.txt这两个文档需在根目录下,因此需在springboot的启动类中增加文档复制到根目录的功能。如:
1@SpringBootApplication 2@EnableSpringUtil 3public class SandboxApplication { 4 public static void main(String[] args) { 5 try { 6 copyFile("validate.txt"); 7 copyFile("public.txt"); 8 } catch (IOException e) { 9 e.printStackTrace(); 10 System.exit(1); 11 } 12 SpringApplication.run(SandboxApplication.class, args); 13 } 14 /** 15 * 从类路径中复制指定文件到运行目录 16 */ 17 private static void copyFile(String fileName) throws IOException { 18 InputStream is = SandboxApplication.class.getResourceAsStream("/" + fileName); 19 Files.copy(is, Paths.get(fileName), StandardCopyOption.REPLACE_EXISTING); 20 } 21 }
配置 repositories
介绍
项目中定义了三个远程仓库,这三个远程仓库主要的作用是提供 Maven 无法在其中央仓库找到的依赖:
- OSGeo Release Repository:这个仓库存储了 Open Source Geospatial Foundation (OSGeo) 项目的正式发布版本。OSGeo 是一个非营利的组织,支持和推广开源地理空间技术和数据的使用。它的仓库包含了许多与地理信息系统 (GIS) 相关的开源项目的构件,例如 GeoTools、GeoServer 等。
- OSGeo Snapshot Repository:这个仓库包含了 OSGeo 项目的开发快照版本。快照版本通常是开发过程中的临时版本,可能包含最新的功能和修复,但也可能不稳定。使用这个仓库可以让你获取到这些项目最新的开发状态。
- GeoSolutions Repository:GeoSolutions 是一个提供地理空间解决方案的公司,其 Maven 仓库可能包含了一些与其产品(例如 GeoServer)相关的依赖。使用这个仓库可以让你使用到 GeoSolutions 提供的依赖。
当在项目中添加一个依赖时,如果 Maven 在本地仓库中找不到这个依赖,它就会去这些远程仓库中查找。因此,这些仓库的声明使得你可以在项目中使用 OSGeo 和 GeoSolutions 提供的依赖。
使用
1<!-- 导geotools包仓库地址 --> 2<repositories> 3 <repository> 4 <id>osgeo</id> 5 <name>OSGeo Release Repository</name> 6 <url>https://repo.osgeo.org/repository/release/</url> 7 <snapshots> 8 <enabled>false</enabled> 9 </snapshots> 10 <releases> 11 <enabled>true</enabled> 12 </releases> 13 </repository> 14 <repository> 15 <id>osgeo-snapshot</id> 16 <name>OSGeo Snapshot Repository</name> 17 <url>https://repo.osgeo.org/repository/snapshot/</url> 18 <snapshots> 19 <enabled>true</enabled> 20 </snapshots> 21 <releases> 22 <enabled>false</enabled> 23 </releases> 24 </repository> 25 <!--GeoServer --> 26 <repository> 27 <id>GeoSolutions</id> 28 <url>http://maven.geo-solutions.it/</url> 29 </repository> 30</repositories>
🍌 工具类的使用
简介
工具类(Utility Class)通常被用于执行通用的、跨领域的任务,这些任务可能在多个地方被重复使用。这些类通常都是静态的,包含一组静态方法,用于无状态的操作,例如字符串处理,日期和时间转换,数学计算等。
工具类(Utility Class)在领域驱动设计(DDD)中的应用
在领域驱动设计(DDD)中,工具类是一种特殊类型的类,主要用于提供一些通用的、无状态的方法,以支持各种常见操作。这些操作可能会跨越多个领域,例如字符串处理、日期和时间转换、数学计算等。
工具类的特点是它们通常是静态的,用于封装和重用那些无需访问对象状态的方法。
然而,工具类在 DDD 中的使用应当谨慎。由于它们通常都是无状态的和非上下文的,如果过度使用,可能会导致领域模型的丰富性和表达性降低。因此,在创建工具类时,我们应当确保这些类所提供的功能确实是通用的、跨领域的,且不能通过领域对象来合理实现。
索引管理工具-IndexManagementUtils
删除指定索引-deleteIndex
介绍
deleteIndex 是一个用于删除 Elasticsearch 中指定索引的方法。它接收一个 Elasticsearch 客户端实例和要删除的索引名称作为参数。
如果指定的索引存在,该方法将删除该索引。如果指定的索引不存在,该方法将不执行任何操作并返回 true。如果在删除索引的过程中发生任何异常,该方法将抛出一个运行时异常。
实现
1/** 2 * 删除指定索引。 3 * 4 * @param tableName 要删除的索引名称 5 * @return 如果成功删除索引或索引不存在,返回 true;如果发生异常,将抛出运行时异常 6 */ 7public static boolean deleteIndex(ElasticsearchClient client,String tableName) { 8 try { 9 // 使用客户端的 indices().delete 方法来删除索引 10 client.indices().delete( 11 builder -> builder.index(tableName) 12 ); 13 } catch (IOException e) { 14 throw new RuntimeException(e); 15 } catch (ElasticsearchException e) { 16 // 原本就没有该index,无需删除 17 return true; 18 } 19 return true; 20}
使用
使用此方法时,你需要提供一个 Elasticsearch 客户端实例和要删除的索引名称。例如:
1 @Resource 2 private ElasticsearchClient client; // 获取 Elasticsearch 客户端实例 3 String tableName = "myindex"; // 指定要删除的索引名称 4 IndexManagementUtils.deleteIndex(client, tableName); // 调用方法删除索引
检查特定索引是否存在-indexExist
介绍
indexExist 是一个用于检查 Elasticsearch 中特定索引是否存在的方法。它接收一个 Elasticsearch 客户端实例和要检查的索引名称作为参数。
如果指定的索引存在,该方法将返回 true。如果指定的索引不存在,或者在检查过程中发生任何异常,该方法将返回 false。
实现
1/** 2 * 检查特定索引是否存在。 3 * 4 * @param tablename 索引名称 5 * @return 如果索引存在,返回 true;如果发生异常或索引不存在,返回 false 6 */ 7public static boolean indexExist(ElasticsearchClient client,String tablename) { 8 try { 9 // 使用 indices().exists 方法检查索引是否存在 10 BooleanResponse isExists = client.indices().exists( 11 new ExistsRequest.Builder() 12 .index(tablename) 13 .build() 14 ); 15 return isExists.value(); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 return false; 19 } 20}
使用
使用此方法时,你需要提供一个 Elasticsearch 客户端实例和要检查的索引名称。例如:
1 @Resource 2 private ElasticsearchClient client; // 获取 Elasticsearch 客户端实例 3 String tablename = "myindex"; // 指定要检查的索引名称 4 boolean exist = IndexManagementUtils.indexExist(client, tablename); // 调用方法检查索引是否存在
如果索引存在,exist 变量的值将为 true;否则,它的值将为 false。
创建映射-createMapping
介绍
createMapping 是一个用于在 Elasticsearch 中动态创建索引映射的方法。这个方法会根据提供的字段映射(fieldMap)推断出字段的类型,并生成相应的索引映射模板。
此方法还包含一个自然语言处理(NLP)选项,如果设置为 true,它将为每个字段添加一个名为 fieldName_vector 的向量字段,这个向量字段用于存储该字段的词向量。这在自然语言处理和文本相似性搜索中非常有用。
此外,该方法还允许你添加别名(big_table_name)到映射中,这样可以在不知道具体索引名称的情况下进行搜索。
实现
1/** 2 * 根据字段map推断出Object的类型 3 * 优先级:日期 >> 整形 >> 长整型 >> 浮点型 >> 字符串 4 * 5 * @param fieldMap 6 * @return 7 */ 8 public static String createMapping(Map<String, Object> fieldMap, Boolean nlp,List<String> big_table_name) { 9 List<String> keyList = fieldMap.keySet().stream().toList(); 10 StringBuilder mappingTemplateBuilder = new StringBuilder(); 11 String vectorName = null; 12 for (int i = 0; i < keyList.size(); i++) { 13 String fieldName = keyList.get(i); 14 Object fieldValue = fieldMap.get(fieldName); 15 if (fieldValue instanceof Date) { 16 vectorName = "\"" + fieldName + "\": {\"type\": \"date\",\"format\": \"yyyy/MM/dd||epoch_millis||strict_date_optional_time||strict_year||strict_year_month||yyyyMM||strict_year_month_day||basic_date||strict_date_hour||yyyy-MM-dd HH||yyyyMMdd'T'HH||yyyyMMdd HH||strict_date_hour_minute||yyyy-MM-dd HH:mm||yyyyMMdd'T'HH:mm||yyyyMMdd HH:mm||strict_date_hour_minute_second||yyyy-MM-dd HH:mm:ss||yyyyMMdd'T'HH:mm:ss||yyyyMMdd HH:mm:ss||strict_date_hour_minute_second_millis||yyyy-MM-dd HH:mm:ss.SSS||yyyyMMdd'T'HH:mm:ss.SSS||yyyyMMdd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSSZ||epoch_millis\"},"; 17 } else if (fieldValue instanceof Integer) { 18 vectorName = "\"" + fieldName + "\": {\"type\": \"integer\"},"; 19 } else if (fieldValue instanceof Long) { 20 vectorName = "\"" + fieldName + "\": {\"type\": \"long\"},"; 21 } else if (fieldValue instanceof Double) { 22 vectorName = "\"" + fieldName + "\": {\"type\": \"float\"},"; 23 } else if (fieldValue instanceof String) { 24 vectorName = "\"" + fieldName + "\": {\"type\": \"text\",\"fields\": {\"keyword\": {\"ignore_above\": 256,\"type\": \"keyword\"}}},"; 25 } 26 mappingTemplateBuilder.append(vectorName); 27 } 28 if (nlp) { 29 // 自然语言mapping定义 30 for (int i = 0; i < keyList.size(); i++) { 31 String fieldName = keyList.get(i); 32 vectorName = "\"" + fieldName + "_vector\": {\n" + 33 " \"type\": \"dense_vector\",\n" + 34 " \"dims\": 768,\n" + 35 " \"index\": true,\n" + 36 " \"similarity\": \"l2_norm\"\n" + 37 " },"; 38 mappingTemplateBuilder.append(vectorName); 39 } 40 } 41 // 去除最后一个逗号 42 mappingTemplateBuilder.deleteCharAt(mappingTemplateBuilder.length() - 1); 43 //加入别名 44 String aliases[] = new String[big_table_name.size()]; 45 big_table_name.toArray(aliases); 46 JSONObject aliasesObject = new JSONObject(); 47 aliasesObject.put("data_big_table", new JSONObject()); 48 for (String alias : aliases) { 49 aliasesObject.put(alias, new JSONObject()); 50 } 51 // 构建mapping 52 String MAPPING_TEMPLATE = 53 "{\n" + 54 " \"mappings\": {\n" + 55 " \"properties\": {\n" + 56 " \"@timestamp\": {\n" + 57 " \"format\": \"epoch_millis||strict_date_optional_time||strict_year||strict_year_month||yyyyMM||strict_year_month_day||basic_date||strict_date_hour||yyyy-MM-dd HH||yyyyMMdd'T'HH||yyyyMMdd HH||strict_date_hour_minute||yyyy-MM-dd HH:mm||yyyyMMdd'T'HH:mm||yyyyMMdd HH:mm||strict_date_hour_minute_second||yyyy-MM-dd HH:mm:ss||yyyyMMdd'T'HH:mm:ss||yyyyMMdd HH:mm:ss||strict_date_hour_minute_second_millis||yyyy-MM-dd HH:mm:ss.SSS||yyyyMMdd'T'HH:mm:ss.SSS||yyyyMMdd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSSZ||epoch_millis\",\n" + 58 " \"type\": \"date\"\n" + 59 " },\n" + 60 " \"vector_geojson\": {\n" + 61 " \"type\": \"geo_shape\"\n" + 62 " },\n" + 63 " \"geo_num_range\": {\n" + 64 " \"type\": \"long_range\",\n" + 65 " \"doc_values\": false\n" + 66 " },\n" + 67 " \"geo_num\": {\n" + 68 " \"type\": \"keyword\",\n" + 69 " \"fields\": {\n" + 70 " \"geo_num_analyzed\": {\n" + 71 " \"analyzer\": \"geonum4_analyzer\",\n" + 72 " \"type\": \"text\"\n" + 73 " }\n" + 74 " },\n" + 75 " \"doc_values\": false\n" + 76 " },\n" + 77 " \"geo_height\": {\n" + 78 " \"type\": \"double_range\",\n" + 79 " \"doc_values\": false\n" + 80 " },\n" + mappingTemplateBuilder + 81 " }\n" + 82 " }\n" + 83// "}\n" + 84 "," + 85 " \"settings\": {\n" + 86 " \"index\": {\n" + 87 " \"number_of_shards\": \"5\",\n" + 88 " \"analysis\": {\n" + 89 " \"analyzer\": {\n" + 90 " \"geonum4_analyzer\": {\n" + 91 " \"filter\": [\n" + 92 " \"uppercase\",\n" + 93 " \"asciifolding\"\n" + 94 " ],\n" + 95 " \"type\": \"custom\",\n" + 96 " \"tokenizer\": \"my_tokenizer\"\n" + 97 " }\n" + 98 " },\n" + 99 " \"tokenizer\": {\n" + 100 " \"my_tokenizer\": {\n" + 101 " \"token_chars\": [\n" + 102 " \"letter\",\n" + 103 " \"digit\"\n" + 104 " ],\n" + 105 " \"min_gram\": \"1\",\n" + 106 " \"type\": \"edge_ngram\",\n" + 107 " \"max_gram\": \"32\"\n" + 108 " }\n" + 109 " }\n" + 110 " },\n" + 111 " \"number_of_replicas\": \"1\"\n" + 112 " }\n" + 113 " }\n" +",\n" + 114 " \"aliases\":\n" +aliasesObject + 115 "}"; 116 return MAPPING_TEMPLATE; 117 }
使用
使用此方法时,你需要提供一个包含字段名称和字段类型的映射,一个指示是否启用自然语言处理的布尔值,以及一个别名列表。例如:
1Map<String, Object> fieldMap = new HashMap<>(); 2fieldMap.put("title", "草地"); 3fieldMap.put("publish_date", 2023-10-13 00:00:00); 4fieldMap.put("view_count", 4); 5fieldMap.put("rating", 2.556); 6List<String> big_table_name = Arrays.asList("alias1", "alias2"); 7String mapping = IndexManagementUtils.createMapping(fieldMap, true, big_table_name);
以上代码将创建一个包含 title,publish_date,view_count,rating 字段的映射模板,其中,title 是文本类型,publish_date 是日期类型,view_count 是整型,rating 是浮点型。此外,由于启用了自然语言处理,所以每个字段都会有一个对应的向量字段。最后,映射模板还包含 alias1 和 alias2 这两个别名。
创建索引-createIndex
介绍
在 Elasticsearch 中,索引是存储数据的地方,类似于传统数据库中的“数据库”。创建索引是 Elasticsearch 数据操作的基础步骤之一。每个索引都有一个映射(mapping)定义,它决定了索引中的字段如何存储和搜索。
createIndex 方法是一个简单的示例,用于创建新的 Elasticsearch 索引。这个方法需要 Elasticsearch 客户端实例、新索引的名称以及映射配置。
实现
1/** 2 * 创建一个新的 Elasticsearch 索引。 3 * 4 * @param client Elasticsearch 客户端实例,用于与 Elasticsearch 集群通信。 5 * @param tablename 要创建的新索引的名称。 6 * @param mapping 新索引的映射配置,以 JSON 格式表示。映射定义了索引中文档的字段及其数据类型。 7 */ 8public static void createIndex(ElasticsearchClient client,String tablename, String mapping) { 9 CreateIndexRequest request = CreateIndexRequest.of(builder -> 10 builder.index(tablename) 11 .withJson(new StringReader(mapping)) 12 ); 13 //发送请求 14 try { 15 client.indices().create(request); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19}
在这个使用示例中,我们首先创建了一个 CreateIndexRequest,并通过构造器设置了索引名称和映射配置。然后,我们通过 Elasticsearch 客户端的 indices().create(request) 方法发送了创建索引的请求。
映射配置是以 JSON 格式提供的,它描述了索引中的字段以及相应的数据类型。例如,一个简单的映射配置可能看起来像这样:
1{ 2 "mappings": { 3 "properties": { 4 "title": { 5 "type": "text" 6 }, 7 "publish_date": { 8 "type": "date" 9 } 10 } 11 } 12}
在这个示例中,我们定义了两个字段:title 和 publish_date,并分别设置其类型为 text 和 date。
使用
1 @Resource 2 private ElasticsearchClient client; // 获取 Elasticsearch 客户端实例 3 // 定义新索引的名称 4 String indexName = "my_new_index"; 5 6 // 定义新索引的映射 7 String mapping = "{" 8 + "\"properties\": {" 9 + "\"field1\": {\"type\": \"text\"}," 10 + "\"field2\": {\"type\": \"integer\"}," 11 + "\"field3\": {\"type\": \"date\", \"format\": \"epoch_millis\"}" 12 + "}" 13 + "}"; 14 15 // 调用 createIndex 方法创建新索引 16 IndexManagementUtils.createIndex(client, indexName, mapping);
更新索引映射-updateIndexMapping
介绍
在 Elasticsearch 中,索引映射定义了索引中的字段以及相应的数据类型。有时,我们可能需要在索引创建后更新其映射,比如,添加新字段或修改字段类型。updateIndexMapping 方法就是用来实现这个功能的。它首先获取当前索引的映射信息,然后根据提供的新字段和类型信息,创建一个新的映射,并更新到索引中。
实现
1/** 2 * 更新 Elasticsearch 索引的映射。 3 * 4 * @param client Elasticsearch 客户端实例,用于与 Elasticsearch 集群通信。 5 * @paramtable_name 要更新的索引的名称。 6 * @param fieldMap 包含新字段及其对应类型的映射。 7 * @throws Exception 如果在更新过程中出现问题,会抛出异常。 8 */ 9 public static void updateIndexMapping(ElasticsearchClient client,String table_name, Map<String, Object> fieldMap) throws Exception { 10 Map<String, Object> newFieldMap = new HashMap<>(); 11 Map<String, String> oldFieldMap = new HashMap<>(); 12 // 获取旧的映射的数据信息 13 GetMappingResponse response = client.indices().getMapping(g -> g.index(table_name)); 14 Map<String, Property> mappingSource = response.get(table_name).mappings().properties(); 15 // 解析旧的映射的数据信息(遍历属性获取字段名和字段类型) 16 for (Map.Entry<String, Property> entry : mappingSource.entrySet()) { 17 String fieldName = entry.getKey(); 18 String fieldType = entry.getValue()._kind().jsonValue(); 19 //存为oldFieldMap 20 oldFieldMap.put(fieldName, fieldType); 21 } 22 //将新的要素字段名和字段类型存储在map 23 Map<String, String> map = new HashMap<>(); 24 List<String> keyLists = fieldMap.keySet().stream().toList(); 25 for (int i = 0; i < keyLists.size(); i++) { 26 String fieldName = keyLists.get(i); 27 Object fieldValue = fieldMap.get(fieldName); 28 if (fieldValue instanceof Date) { 29 map.put(fieldName, "date"); 30 } else if (fieldValue instanceof Integer) { 31 map.put(fieldName, "integer"); 32 } else if (fieldValue instanceof Long) { 33 map.put(fieldName, "long"); 34 } else if (fieldValue instanceof Double) { 35 map.put(fieldName, "float"); 36 } else if (fieldValue instanceof String) { 37 map.put(fieldName, "text"); 38 } 39 } 40 //遍历新的字段信息,与旧的字段信息做比较 41 for (Map.Entry<String, String> entrys : map.entrySet()) { 42 String fieldName = entrys.getKey(); 43 String fieldType = entrys.getValue(); 44 // 检查字段名是否在map中,如果存在则比较字段类型 45 if (oldFieldMap.containsKey(fieldName)) { 46 String expectedFieldType = map.get(fieldName); 47 if (fieldType.equals(expectedFieldType)) { 48// log.info("字段名相同,字段类型匹配,不用进行字段修改"); 49 } else { 50// log.info("字段名相同,字段类型不匹配,后续再进行逻辑优先级修改"); 51 } 52 } else { 53// log.info("字段名不相同,可以直接获取新字段信息中的字段名和字段类型"); 54 newFieldMap.put(fieldName, fieldType); 55 } 56 } 57 log.info("旧映射与新映射比较,旧映射没有的字段名和类型为:" + newFieldMap); 58 //拿到新的字段映射后,进行构建新mapping,可以理解为修改映射 59 List<String> keyList = newFieldMap.keySet().stream().toList(); 60 StringBuilder mappingTemplateBuilder = new StringBuilder(); 61 String vectorName = null; 62 for (int i = 0; i < keyList.size(); i++) { 63 String fieldName = keyList.get(i); 64 Object fieldValue = newFieldMap.get(fieldName); 65 if (fieldValue instanceof Date) { 66 vectorName = "\"" + fieldName + "\": {\"type\": \"date\",\"format\": \"yyyy/MM/dd||epoch_millis||strict_date_optional_time||strict_year||strict_year_month||yyyyMM||strict_year_month_day||basic_date||strict_date_hour||yyyy-MM-dd HH||yyyyMMdd'T'HH||yyyyMMdd HH||strict_date_hour_minute||yyyy-MM-dd HH:mm||yyyyMMdd'T'HH:mm||yyyyMMdd HH:mm||strict_date_hour_minute_second||yyyy-MM-dd HH:mm:ss||yyyyMMdd'T'HH:mm:ss||yyyyMMdd HH:mm:ss||strict_date_hour_minute_second_millis||yyyy-MM-dd HH:mm:ss.SSS||yyyyMMdd'T'HH:mm:ss.SSS||yyyyMMdd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSSZ||epoch_millis\"},"; 67 } else if (fieldValue instanceof Integer) { 68 vectorName = "\"" + fieldName + "\": {\"type\": \"integer\"},"; 69 } else if (fieldValue instanceof Long) { 70 vectorName = "\"" + fieldName + "\": {\"type\": \"long\"},"; 71 } else if (fieldValue instanceof Double) { 72 vectorName = "\"" + fieldName + "\": {\"type\": \"float\"},"; 73 } else if (fieldValue instanceof String) { 74 vectorName = "\"" + fieldName + "\": {\"type\": \"text\",\"fields\": {\"keyword\": {\"ignore_above\": 256,\"type\": \"keyword\"}}},"; 75 } 76 mappingTemplateBuilder.append(vectorName); 77 } 78 // 去除最后一个逗号 79 if (newFieldMap.size() == 0) { 80 // newFieldMap为空,不需要去除逗号 81 } else { 82 mappingTemplateBuilder.deleteCharAt(mappingTemplateBuilder.length() - 1); 83 } 84 //构建新映射 85 String fieldMapping = "{\n" + 86 " \"properties\": {\n" + 87 mappingTemplateBuilder + 88 " }\n" + 89 "}"; 90 try { 91 client.indices().putMapping(p -> p 92 .index(table_name) 93 .withJson(new StringReader(fieldMapping)) 94 ); 95 log.info("映射合并-成功"); 96 } catch (IOException e) { 97 e.printStackTrace(); 98 //throw new MappingUpdateException("映射合并过程出现问题"); 99 } 100 }
使用
1 @Resource 2 private ElasticsearchClient client; 3 // 定义要更新的索引的名称 4 String indexName = "my_index"; 5 // 定义一个新的字段映射 6 Map<String, Object> fieldMap = new HashMap<>(); 7 fieldMap.put("newField1", "This is a string"); 8 fieldMap.put("newField2", 123); 9 fieldMap.put("newField3", new Date()); 10 // 调用 updateIndexMapping 方法更新索引映射 11 IndexManagementUtils.updateIndexMapping(client, indexName, fieldMap);
刷新索引-refreshIndex
介绍
Elasticsearch 在索引新的文档或更新现有文档时,并不会立即将这些变更反映到搜索结果中。这是为了优化性能,因为立即反映所有变更会对系统性能产生很大的影响。相反,Elasticsearch 会周期性地自动执行刷新操作,将最近的索引变更反映到搜索结果中。这个刷新间隔默认是一秒。
然而,有时我们可能需要立即看到索引的变更,比如在编写测试或进行调试时。这就是 refreshIndex 方法的用处。它会强制 Elasticsearch 立即执行一次刷新操作,将所有等待的索引变更立即反映到搜索结果中。
实现
1 /** 2 * 刷新到硬盘 3 * @param table_name 4 */ 5 public static void refreshIndex(ElasticsearchClient client,String table_name) { 6 try { 7 client.indices().refresh(r -> r 8 .index(table_name) 9 ); 10// log.info("索引磁盘刷新成功!"); 11 } catch (IOException e) { 12 log.info("索引磁盘刷新失败! "); 13 e.printStackTrace(); 14 } 15 }
使用
1// 创建一个 Elasticsearch 客户端实例 2 @Resource 3 private ElasticsearchClient client; 4 // 定义要刷新的索引的名称 5 String indexName = "my_index"; 6 // 调用 refreshIndex 方法刷新索引 7 IndexManagementUtils.refreshIndex(client, indexName);
入参注解-@ValidationStatusCode
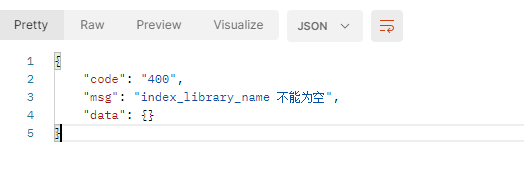
介绍
自定义了一个@ValidationStatusCode注解,在入参时触发错误后,会将自定义的文字错误提示返回
使用
1@ValidationStatusCode(code = "400") 2private String index_library_name;

测试
超时断开 - @Timeout
在一个controller方法中,有时一个业务逻辑执行的时间可能会很长,对于某一个方法,若用户在隔开一段时间后已经不重视该结果了,则可以在一个controller方法上加上@Timeout注解,用于中断该方法的执行。